Wie anderweitig beschrieben habe ich vor einiger Zeit damit angefangen, Analysefunktionen für Podlove-Daten in der statistischen Sprache R zu schreiben.
Über die Feiertage habe ich nun den ganzen Code überarbeitet und ein echtes (d.h. via devtools installierbares) Package gebaut. Es heisst “podlover” und hat hier sein Zuhause:
Das Paket kann alles, was die alten Funktionen auch schon konnten, und noch etwas mehr:
- Daten aus der Wordpress MySQL-Datenbank des Podcasts holen
- Daten zusammenführen und säubern (entweder via Download oder mit lokalen CSV-Tabellen)
- Ausgabe von Downloadkurven mit verschiedenen Parametern:
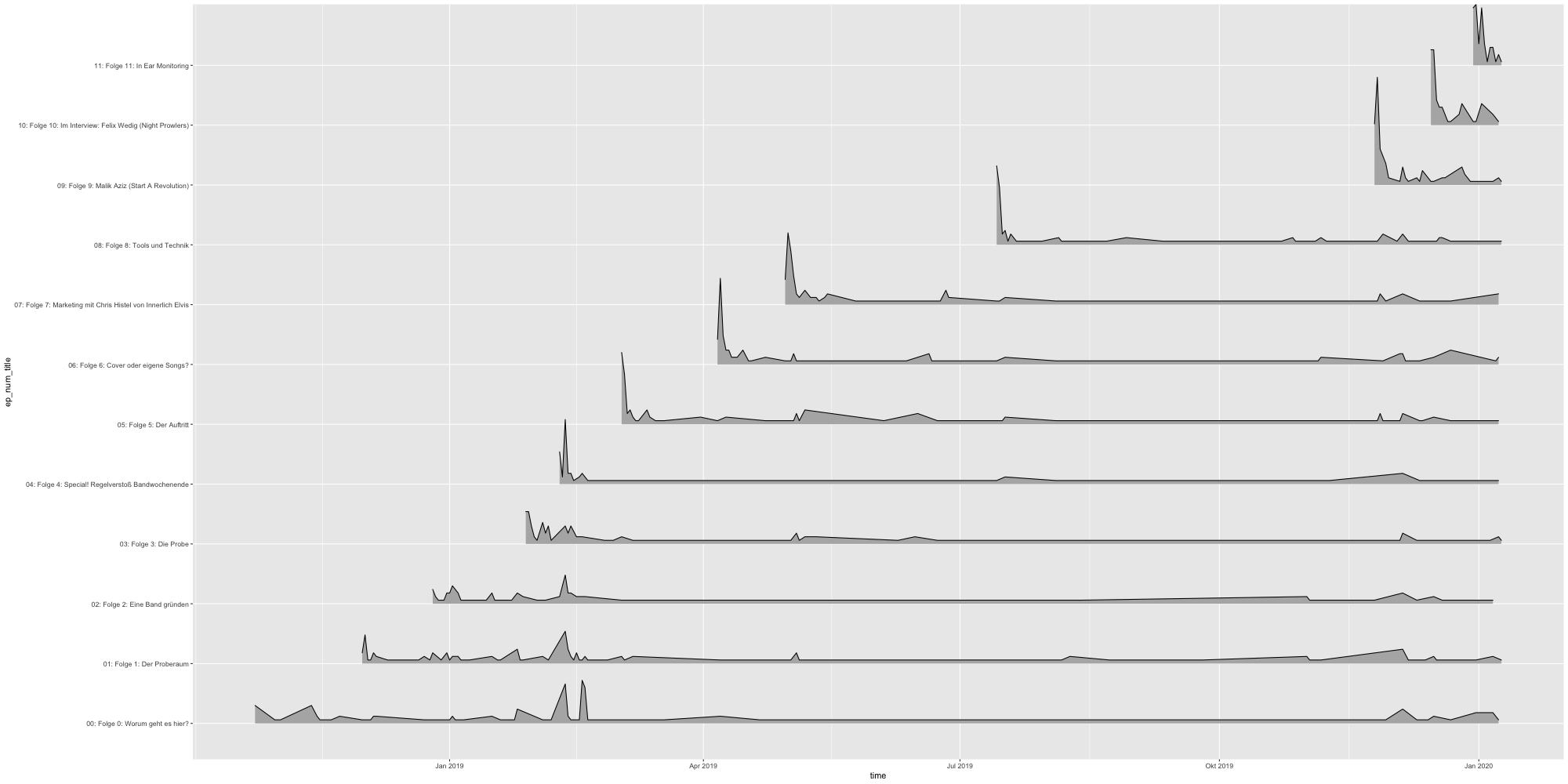
- Gesamtdownloads oder Gruppierung nach Episodentitel, -nummer, Quelle (z.B. Feed vs. Webplayer) und Endgerät
- kumulierte Kurven (Gesamtzahl über Zeit) oder nichtkumulierte Kurven
- absolute Zeitpunkte (Datum der Veröffentlichung) vs. relative Zeitpunkte (Zeit seit Veröffentlichung)
- grafische Darstellungsoptionen, z.B. Kurvenart, Farben, Beschriftung etc.
- Leistungslisten pro Episode (totale Downloads, durchschnittliche Downloads, durchschnittliche Downloads für bestimmte Zeiträume)
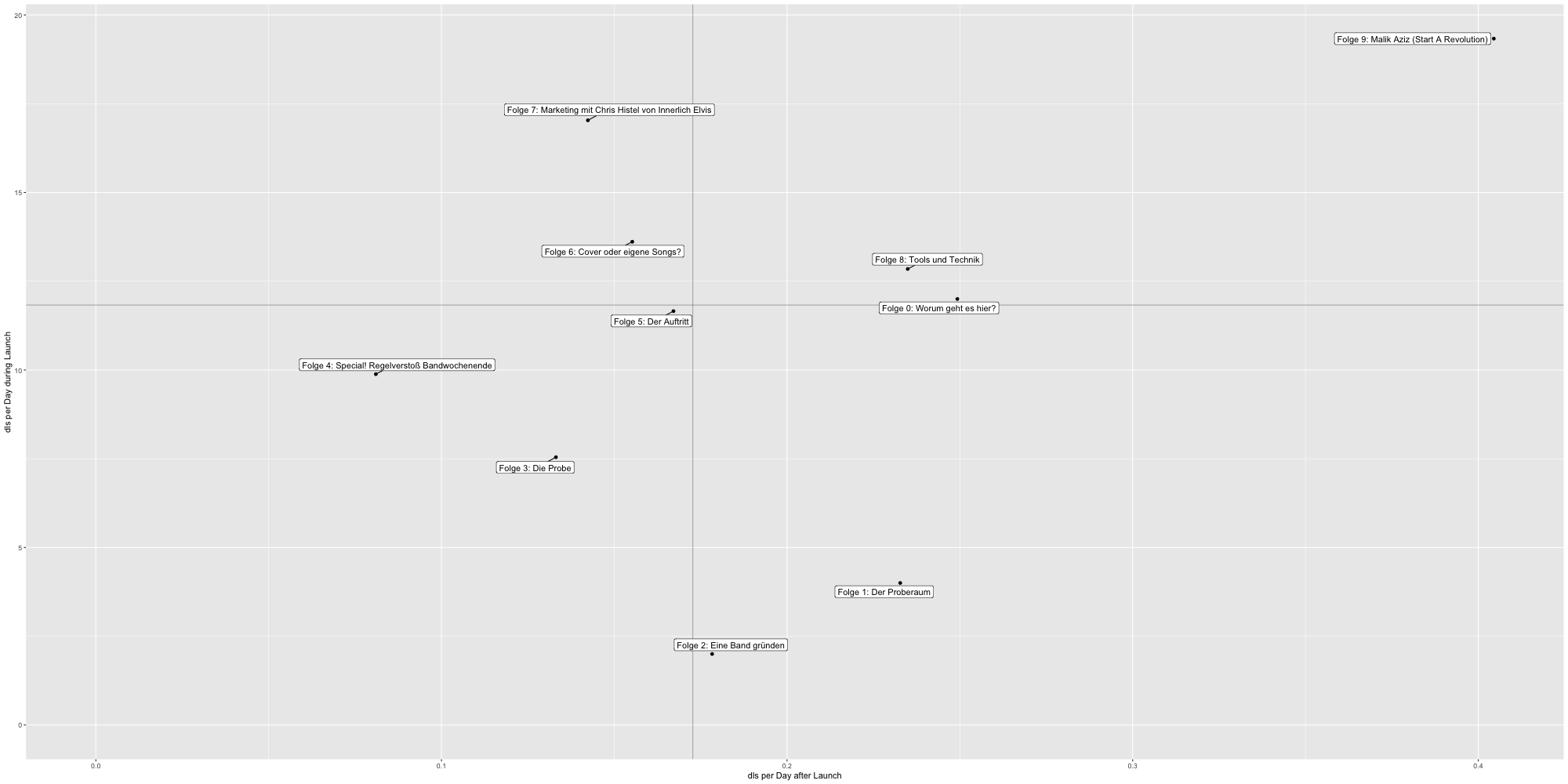
- Leistungsvergleich im 2x2-Diagramm (Veröffentlichung vs. Langzeit)
- Regressionsanalyse von Downloads X Tage nach Veröffentlichung vs. Episodennummer oder Zeit: Damit lässt sich berechnen und darstellen, ob die Downloads tendenziell steigen oder sinken (inspiriert von @rahra s Prototyp)
- Eine Funktion, um zufällige Downloadzahlen zu generieren, womit sich die Funktionen testen lassen
Alle Funktionen sind in den Helpfiles dokumentiert. Eine umfangreiche Erklärung mit Beispielen findet ihr hier oder in der Vignette des Pakets. Tests und Feedback sind willkommen.
Einen herzlichen Dank an @schaarsen für seine freundliche Datenspende!
Hier noch eine kleine Gallerie von Dingen, die podlover kann:
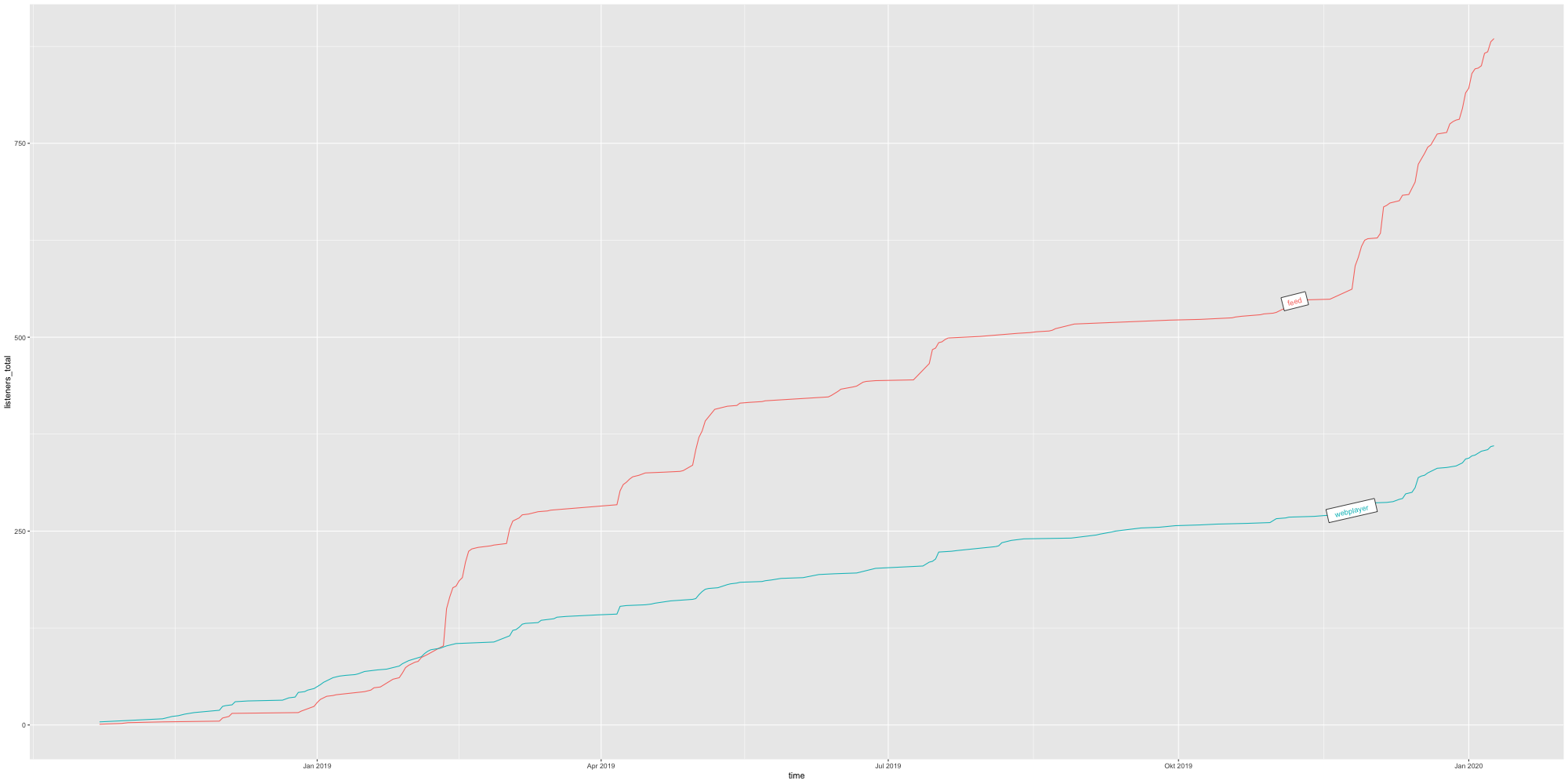
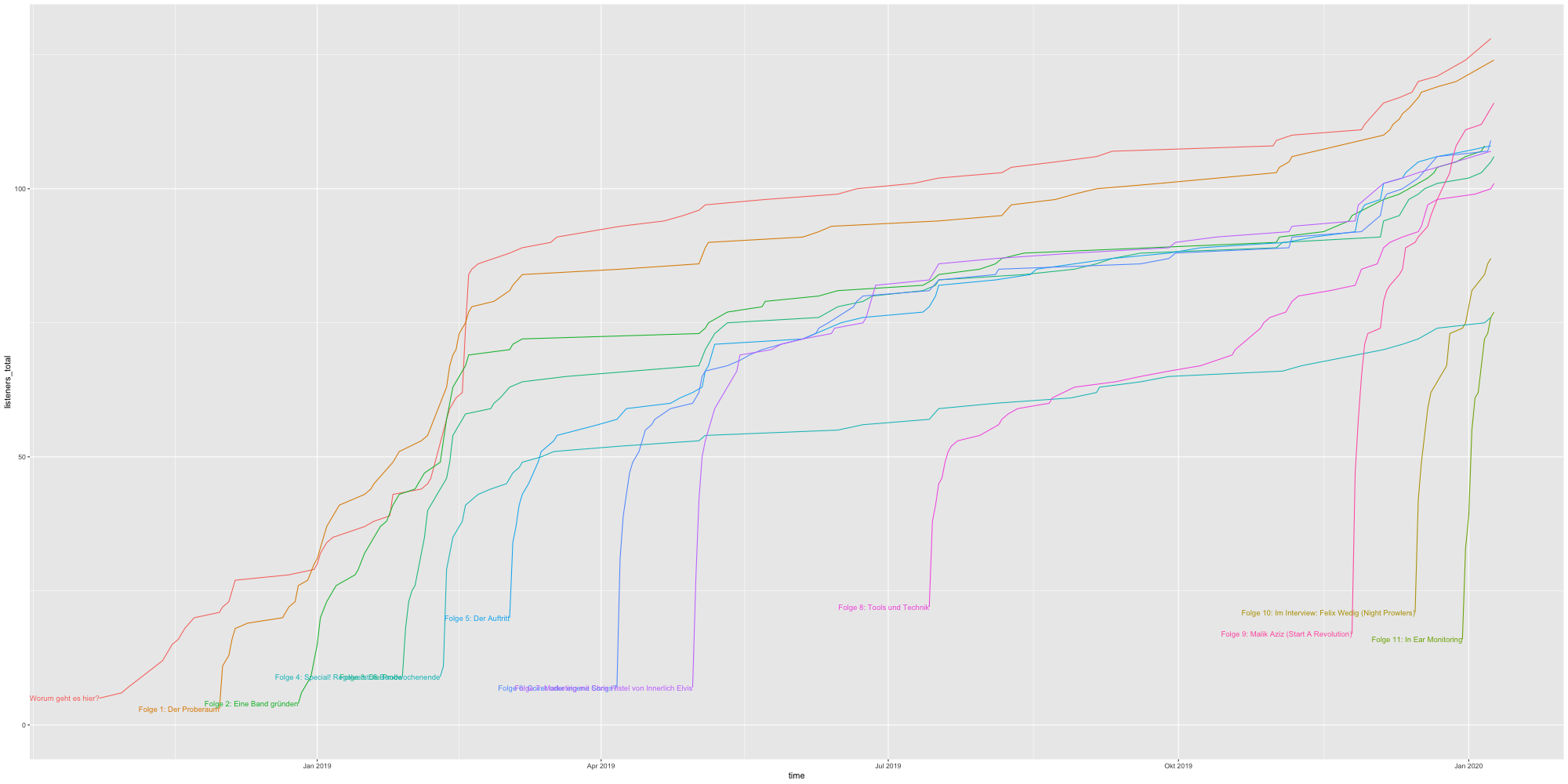
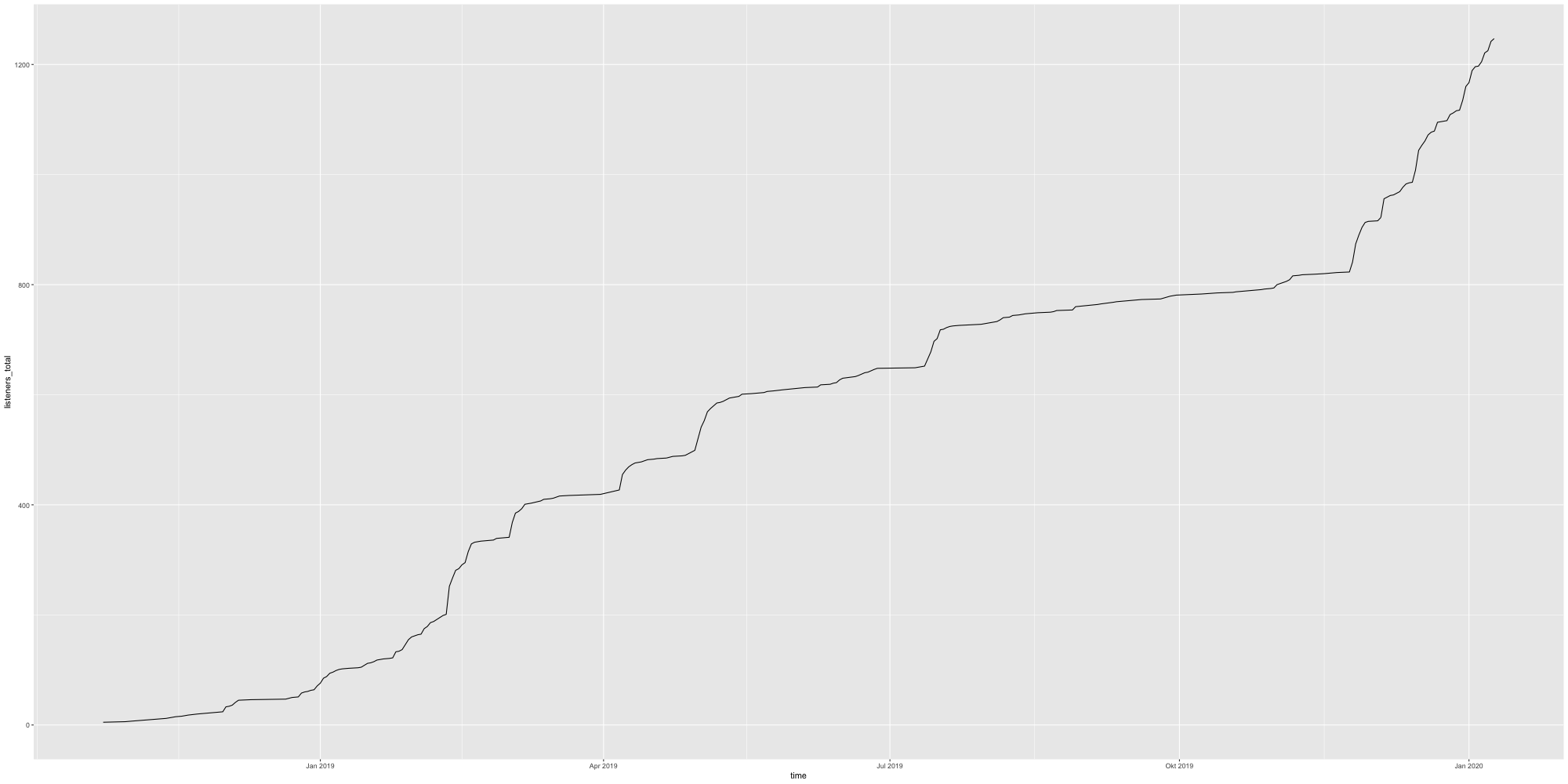
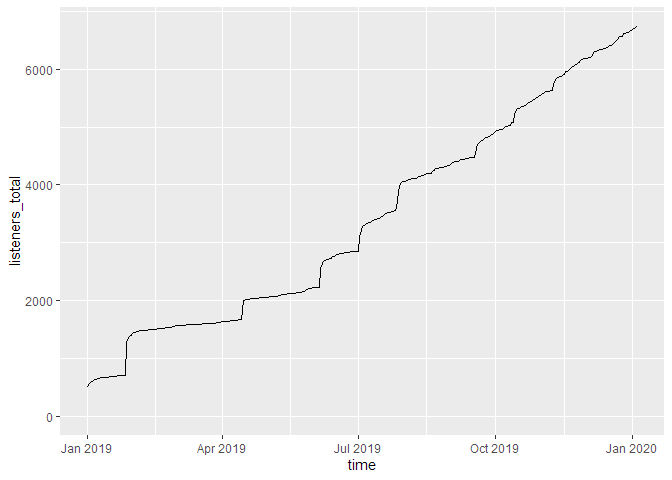
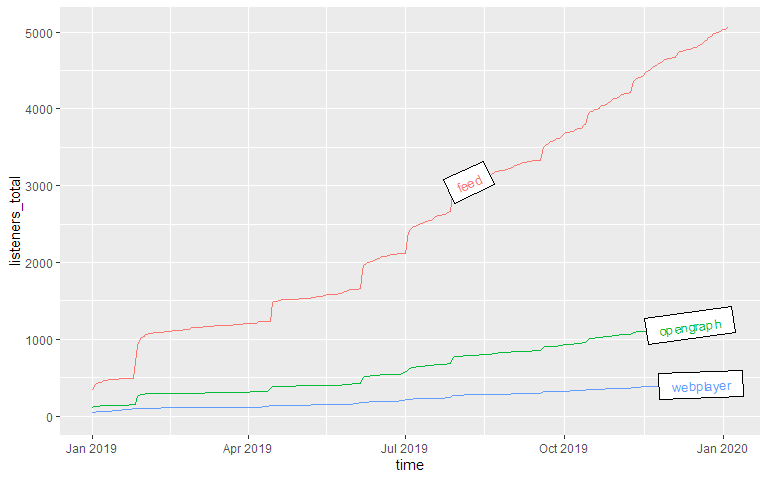
Totale Downloads über Zeit (kumuliert)
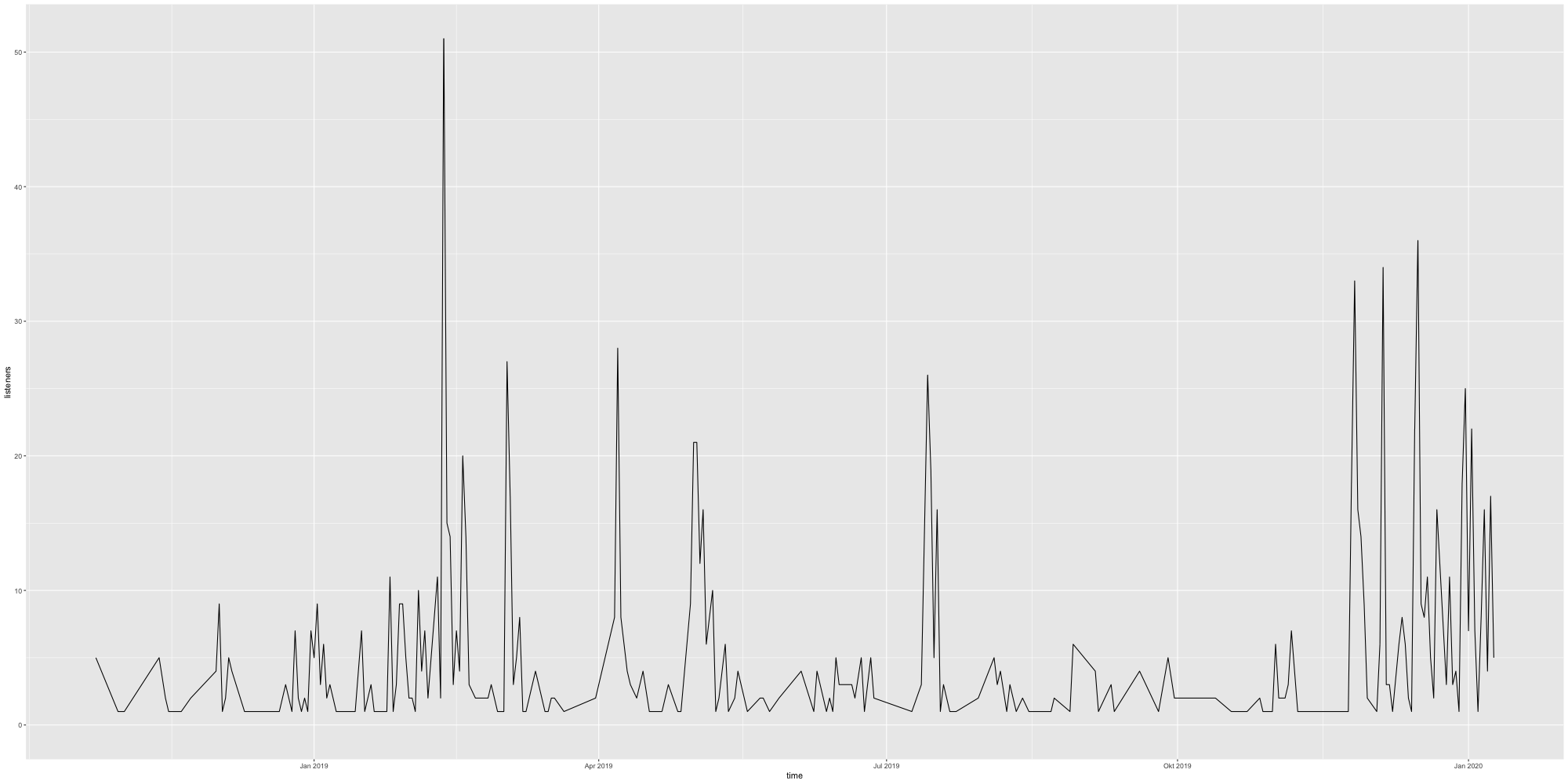
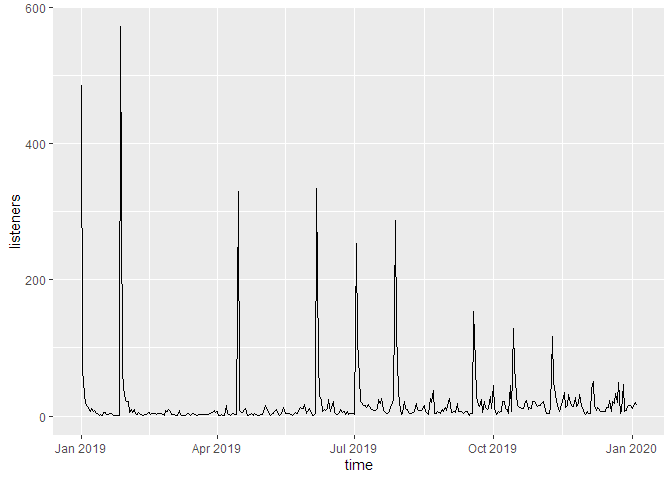
Totale Downloads über Zeit (nicht kumuliert)
Podast-Zusammenfassung
#> 'downloads':
#>
#> A podcast with 10 episodes, released between 2019-01-01 and 2019-12-05.
#>
#> Total runtime: 11m 4d 22H 0M 0S.
#> Average time between episodes: 2928240s (~4.84 weeks).
#>
#> Episodes were downloaded 6739 times between 2019-01-01 and 2020-01-04.
#>
#> Downloads per episode: 673.9
#> min: 132 | 25p: 375 | med: 703 | 75p: 791 | max: 1327
#>
#> Downloads per day: 18.3
#> min: 1 | 25p: 3 | med: 7 | 75p: 16 | max: 572
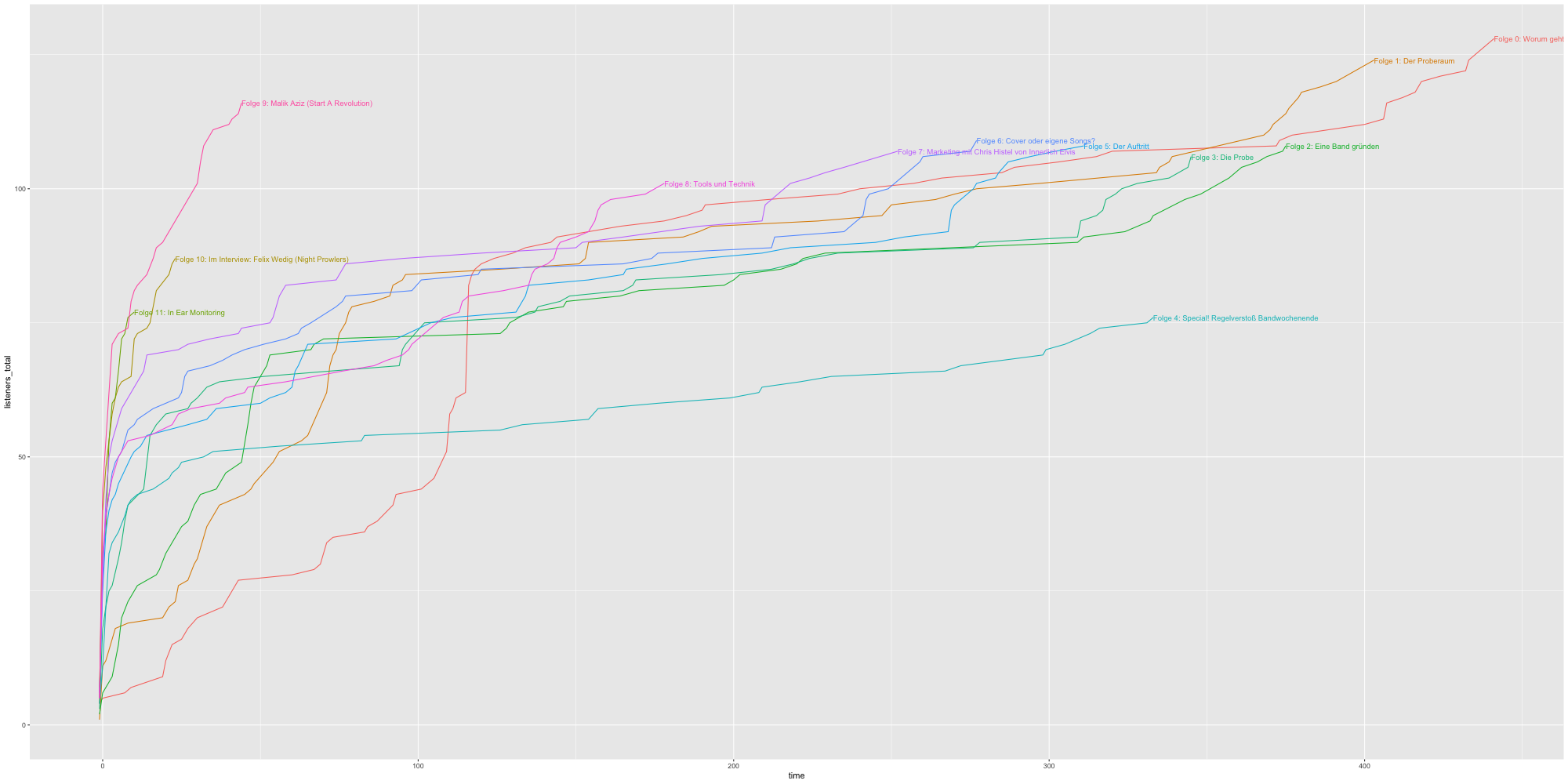
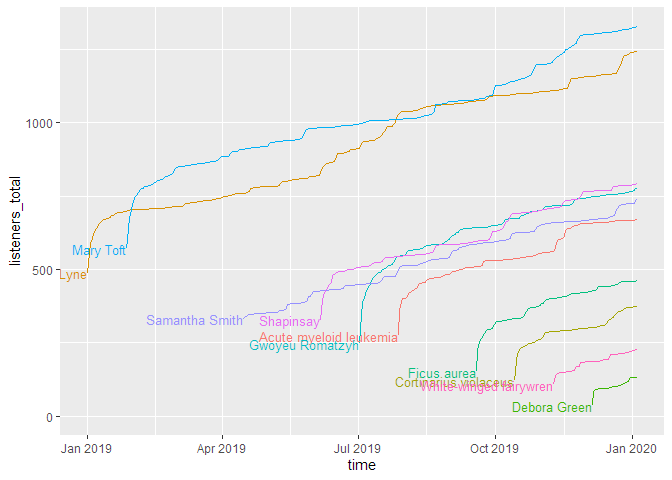
Downloads pro Episode mit absoluter Zeitskala
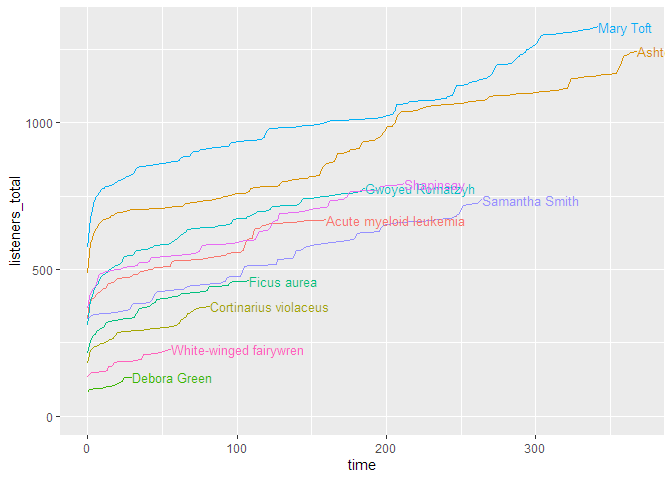
Downloads pro Episode mit relativer Zeitskala
Downloads pro Quelle
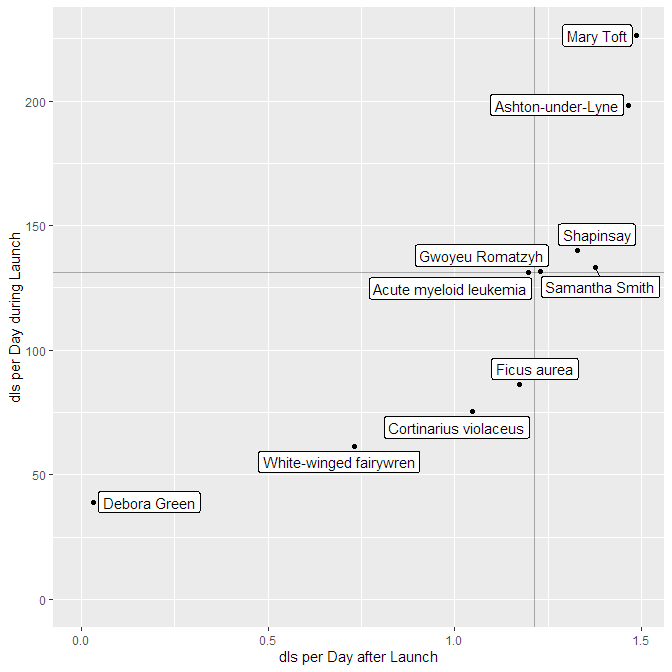
Durchschnittliche Downloads während der Launchperiode
#> title dls_per_day_at_launch
#> <fct> <dbl>
#> 1 Mary Toft 226.
#> 2 Ashton-under-Lyne 198.
#> 3 Shapinsay 140
#> 4 Samantha Smith 133.
#> 5 Gwoyeu Romatzyh 132.
#> 6 Acute myeloid leukemia 131
#> 7 Ficus aurea 86.2
#> 8 Cortinarius violaceus 75.4
#> 9 White-winged fairywren 61.5
#> 10 Debora Green 39
Leistungsanalyse Launch vs. Langzeit
Regressionsanalyse Downloads vs. Episodennummer
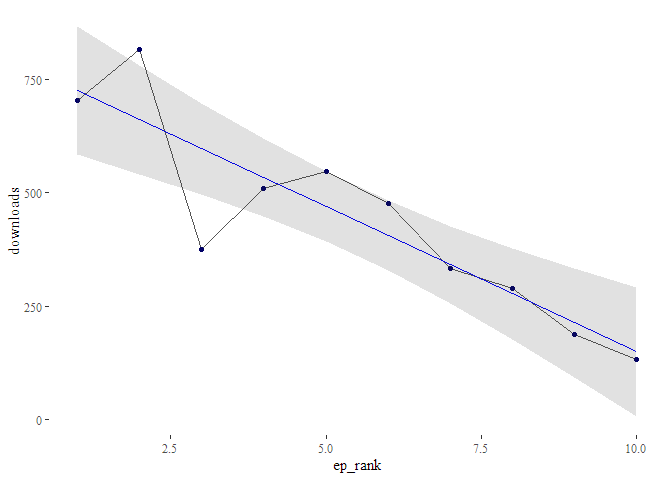
Regressionsanalyse: Statisches Modell mit Signifikanzen
#> Call:
#> stats::lm(formula = formula_string, data = df_regression_data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -222.21 -23.69 -11.74 57.09 155.70
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 789.47 71.28 11.075 3.94e-06 ***
#> ep_rank -64.08 11.49 -5.578 0.000523 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 104.3 on 8 degrees of freedom
#> Multiple R-squared: 0.7955, Adjusted R-squared: 0.7699
#> F-statistic: 31.12 on 1 and 8 DF, p-value: 0.0005233 viel Respekt!!!
viel Respekt!!!