Mit dem ZOOM-H6 kann man bis zu 24bit bei einer Samplerate von 96kHz aufzeichnen. Was bedeutet das eigentlich?
Die Bittiefe von 24bit bezeichnet die Aufnahmegenauigkeit zu einem Zeitpunkt. Bei einer Aufzeichnung mit 24bit wird eine reproduzierende Lautsprecherstellung in 16’777’216 Positionen unterschieden. Bei 16bit wären dies nur 65’536 Positionen. Alleine aus dem Gesichtspunkt, dass uns Speicher fast nichts mehr kostet, scheint es ja sinnvoll eine Aufnahme in 24bit in Erwägung ziehen.
Im Aufnahmebereich hat sich eine andere Einheit als Bit etabliert- dort werden Dezibel verwendet, und im Bezug auf Lautsprecherstellungen bzw. Spannungswerte entspricht der Faktor 2, bzw 1 Bit, gerade 6 Dezibel, bzw. 6dB. Das bedeutet, dass eine Aufzeichnung in 16bit einem theoretischen Dynamikumfang von 96dB entspricht, eine Aufzeichnung in 24bit einem theoretischen Dynamikumfang von 144dB.
Die Aufnahme in 96kHz bezeichnet, wie häufig die reproduzierende Lautsprecherstellung abgetastet wird. Bei tiefen Frequenzen bewegt sich die Lautsprechermembran fast andauernd scheinbar kontinuierlich in eine Richtung- da wäre die häufige Abtastung fehl am Platz. Geht es aber um hohe Frequenzen, so sind hohe Abtastraten sehr wichtig. Die höchste Frequenz, die bei einer festen Samplerate von f aufgezeichnet werden kann, ist die Frequenz f/2.
Eine Aufzeichnung mit einer Abtastrate von 44kHz kann also maximal Töne bis zu einer Frequenz von 22kHz abbilden, eine Aufzeichnung mit einer Abtastrate von 96kHz maximal bis zu einer Frequenz von 48kHz.
Was ist davon für unsere Aufzeichnungen relevant?
Zunächst zum Dynamikumfang: Nimmt man ein schlechtes Mikro, das richtig viel rauscht, so macht es nicht Sinn genauer als das Rauschen aufzunehmen. Dazu vergleicht man den “Pegel” des Rauschens mit dem “Pegel” des Signals und bestimmt das Verhältnis- das ist dann der Signal-zu-Rausch-Abstand, oder “Signal-to-noise-ratio” (SNR). Die englische Bezeichnung ist hier besser, da der deutsche “Abstand” meisstens ohnehin das Verhältnis meint.
Doch geht es nicht nur um das Rauschen der Hardware- Menschen atmen, Computer rauschen, es gibt immer wieder zusätzliche Störquellen, die von der Aufnahmesituation, von der Person, dem Mikro und der Technik abhängen können.
Um das zu illustrieren habe ich hier eine Aufnahme mit dem DT-297 und dem Zoom-H6 mit 24bit in 96kHz in einem relativ stillen Raum erstellt:

Mit der Option --noise kann man in OSPAC genau die Stille herausfiltern und damit den effektiven Signal-zu-Rausch Abstand bestimmen (Bild ist hoch-skaliert):
ospac --raw --noise dynamic-test.wav --output dynamic-noise.wav

Hier das Ergebnis: Das Rauschen in L1-norm (Durchschnitt) und das Maximum des Gesamten:
5.42 Skip.cpp:336 Linf of all: 18077.00
5.42 Skip.cpp:337 L1 of noise: 10.38
5.42 Skip.cpp:342 S/N Ratio : 1741.38, 10.77 bits, 64.60dB
Das Maximum lag also bei etwa -6dB und das Rauschen bei etwa -71dB. Bei der Aufzeichnung mit 24Bit konnte das Gerät bis -144dB aufzeichnen. Davon waren jetzt der Bereich von -144dB bis -71dB reinstes Rauschen- selbst bei dieser recht guten Aufnahmesituation. Eine Aufzeichnung bis -96dB, also in 16Bit, hätte hier vollkommen gereicht.
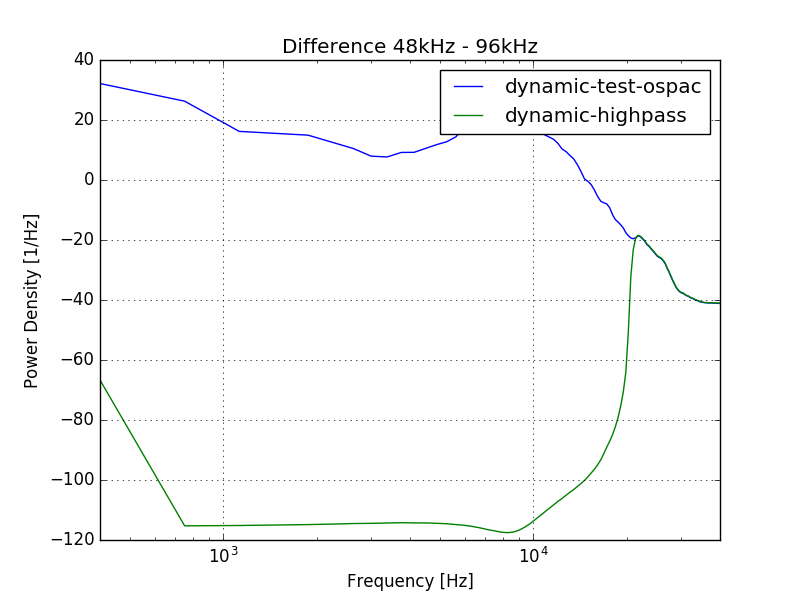
Bei der Aufnahme mit 96kHz erhofft man sich eine besonders gute Auflösung in den hohen Frequenzen. Um das zu analysieren, habe ich die Aufnahme auf 44.1kHz umgerechnet und von der 96kHz Aufnahme abgezogen. Das Ergebnis ist hier- verstärkt um etwa 50dB bis zum Vollausschlag (!):

Also ich weiß, dass die Kopfhörer da warm werden sollten, aber selbst das habe ich nicht bemerkt. Falls da jemand etwas hört- und das auch noch richtig laut- dann macht die Aufnahme mit 96kHz vielleicht wirklich Sinn. Sonst- objektiv betrachtet- eher nicht. Das entspricht auch der Erfahrung mit dem menschlichen Gehör.
Fazit:
Solange ihr also kein besseres Equipment als den DT-297 und den H6 habt, und auch nicht die Sprache durch langsamer Abspielen tiefer klingen lassen wollt, so reichen 44.1/48kHz bei 16Bit vollkommen.
Und wenn ihr eine Aufnahmesituation mal objektiv bewerten wollt- so könnt ihr das mit Ospac tun. Natürlich auch in den GUIs auf Windows oder OS/X.