tl;dr: kann ich meinen Workflow sinnvoll automatisieren, um Arbeit zu sparen? Kann mir US dabei helfen?
long story:
Hallo zusammen, ich wollte mich auch mal zu Wort melden, weil ich gern Ultraschall besser verstehen möchte, um ggf komplett darauf umzusteigen und den Schritt über auphonic sein zu lassen. Das scheint mir aktuell aber zu viel Arbeit zu machen, daher hier mein aktuelles Vorgehen und wo ich Schwierigkeiten sehe:
Aufnahme
1.a ich nehme mich in Reaper/US5 auf, direkt über mein Røde NT-USB, auf Kanal 1. Wenn ich gerade nichts sagen will, während der Aufnahme oder Nebengeräusche vermeiden, dann disarme ich meine Spur, nehme also gar nichts auf und aktiviere sie wieder, wenn ich wieder sprechen will, wodurch ich mehrere Files pro Aufnahme bekomme.
1.b meine Gesprächspartnys nehme ich entweder über die virtuellen Ultraschall-Audio-Geräte mit auf über mumble oder selten mal Skype, so dass sie eine gemeinsame Spur in meiner Aufnahme bekommen. Das reicht für das Angleichen meiner Aufnahme von ihnen mit ihrer eigenen Aufnahme von ihnen gut aus, sofern es keine großen technischen Probleme gab. Oder ich nehme über Studiolink ihre Spuren direkt auf, was angenehm ist, weil ich dann für jedes Gesprächspartny eine eigene Spur bekomme, was allerdings nicht immer so gut funktioniert, dass ich es benutzen kann. Jüngst habe ich das Problem, dass die Kommunikation über Studiolink ein Delay verursacht, das nach 30 min eine Sekunde oder mehr ist. Oft brauche ich also die eigenen Aufnahmespuren meiner Gesprächspartnys, die ich im Nachgang bekomme.
1.c Während der Aufnahme setze ich Kapitelmarken, sofern für das aktuelle Projekt nötig. Ferner setze ich edit-marker für alle Dinge, die mir währenddessen auffallen, wo ich im Schnitt wieder ran muss. So spare ich mir das komplette Anhören der Aufnahmen im Schnitt.
Schnitt
2.a wenn ich separate Spuren bekommen habe, positioniere ich diese anhand ihrer Ausschläge optisch untereinander und mute meine Aufnahme der anderen. Wenn die Aufnahme in Studiolink funktioniert hat, überspringe ich das.
2.b ich setze alle Spuren auf Mono-Downmix und normalisiere sie mit der Funktion ‚common gain‘, um sie alle ungefähr gleich laut zu hören. Ich gehe hierbei davon aus, dass die grundsätzliche Aufnahmelautstärke über die gesamte Länge hinweg gleich ist. Dabei habe ich dann ein paar Ausreißer nach oben. Wenn der Unterschied zwischen den Spitzen und dem normalen Ausschlag zu groß ist, schneide ich links und rechts vom Aussetzer, markiere alles andere der Spur und common-gain-normalisiere den rest nochmal.
2.c Ich schneide den Anfang und das Ende weg, entferne Pausen und schneide manche Momente um, wo zwei Leute gleichzeitig reden. Wenn nötig, entferne ich technische Macken oder andere nicht für die Veröffentlichung passende Elemente.
2.d während des Schnitts optimiere ich die Kapitelmarken und entsorge die Edit-marken, die ich stück für stück abarbeite.
2.e ich gebe den Kapitelmarken Namen.
Export
3.a Die Kapitelmarken exportiere ich in den Projektordner, um sie später bei auphonic wieder händisch einzulesen.
3.b Ich exportiere alle Spuren einzeln (meist als mono) als FLAC 24-Bit in einen Dropbox-Ordner, von wo aus auphonic sie findet, sobald sie hochgeladen sind.
Postproduktion
4.a ich erstelle ein neues Multi-Spur-Projekt bei Auphonic anhand meines für den Podcast vorher festgelegten Presets, das bereits ein bisschen Meta enthält (Podcastcover, Intro, Outro, zu exportierende Dateien, Verlinkung zum FTP-Server, Verknüpfung mit wit.ai für die automatische Spracherkennung)
4.b ich füge meine Spuren zum Projekt hinzu, gebe der Podcastepisode ihren Namen, benenne die Folgennummer korrekt, den Exportdateinamen und füge die Kapitelmarken per Datei-upload hinzu.
4.c auphonic rendert mir meine Datei als m4a, mp3, die Kapitelmarken als txt und das Transkript als vtt und schiebt alles auf meinen Server.
Beitrag erstellen
5.a Ich wechsle zu meiner Wordpress-Seite und erstelle eine neue Episode.
5.b Ich gebe den Namen der Episode ein, füge ein paar Shownotes hinzu, trage die Folgennummer ein, trage den Namen nochmal ein, trage die Folgennummer nochmal als Short-URL-Slug ein und wähle im podlove-plugin meine auphonic-Produktion.
5.c ich speichere einmal, um anschließend neu zu laden, um die im Transkript gefundenen Namen den Beteiligten zuordnen zu können.
5.d ich ändere den Veröffentlichungszeitpunkt, sofern nötig, gebe meinen per Jetpack automatisch veröffentlichten Tweet ein und veröffentliche.
Meine Fragen an euch:
Was kann ich verbessern, um weniger Arbeit zu haben, aber möglichst nicht auf Features für meine Hörys zu verzichten?
Kann ich den US5-Produktionsworkflow nutzen, wenn ich keine Lust habe, sämtliche Momente, in denen bei meinen Produktionen jemand nichts sagt, händisch zu muten oder zu löschen? Das normalisieren auf -23db macht kein common gain und hebt daher auch die ‚stillen‘ Momente mit nur Hintergrundrauschen auf -23db.
danke für’s Lesen!
Arne
p.s.: Ultraschall ist fantastisch und ich würde ohne vermutlich keine Podcasts mehr machen. Oder zumindest erheblich weniger.
Also ich würde hier einen radikalen Umbau vorschlagen, der deinen Workflow massiv verkürzen würde:
Nimme den mit US5 eingeführten „AMP“ Workflow für das Mixing-Mastering. Der hat diverse Vorzüge für dich:
kein Muten/RecDisarm mehr notwendig.
Ja, das Normalisieren auf -23 LUFS hebt auch Störungen an, die dann aber sehr effizient im neu angepassten Dynamics 2 - Filter verschwinden. Das Wenige, was übrig bleibt: einfach aushalten.
Für die Metadaten nimmst du ausschließlich den neuen Export-Assistenten. Am Ende fällt ein „perfektes“ MP3 raus an dem du nichts mehr ändern musst.
Wenn du noch Kapitelbilder zu Kapitelmarken hinzufügst, haben deine Hörys soger mehr als vorher.
Für das Ausrichten von Double-Endern kannst du den entsprechenden Workfow in US 5 probieren, das spart tendenziell auch viel Zeit.
Referenzen:
AMP-Workflow für Mixing und Mastering:
Workflow für Double-Ender:
Export-Assistent:
Marker Dashboard 2 mit Kapitelbildern:
Und wirklich generell: wenn ihr einigermaßen brauchbare Mikros habt und nicht in einer Halle sitzt - vertraut dem AMP-Workflow. Gold-Star Referenz ist der Audiodump Podcast, hör mal rein:
Der @Malik ist hier bleeding edge und passt exakt NICHTS mehr an. Bei zig unterschiedlichen Mikros, alle bis auf ihn über StudioLink. Er stellt Nachts um 2 die in US5 vorgegebenen Presets ein, rendert raus - fertig. Kein Probehören, nichts. Und es klingt: hervorragend.
Das mache ich mittlerweile auch so. Früher hab ich immer noch am Dynamics ein bisschen gedreht, heute einfach normalisieren, dynamics und eq anklicken, beide mit den US5 presets, effekt auf master an, rendern, metadaten, fertig. Auphonic ist echt nur noch backup lösung für zu lästige längere fixes wenn was brummt oder besonders müllig klingt, dann ist das Ergebnis besser als das was ich selber hinkriege. Aber das ist vielleicht für 5% der Fälle relevant – ansonsten nur noch US5 Bordmittel mit den default Einstellungen und es ist super.
das klingt alles zu schön, um wahr zu sein. ich probier das mal aus und melde mich dann wieder. auf den ersten Blick verzichte ich dadurch auf den Transkript-service von wit.ai, was jetzt nicht so dramatisch wäre, muss mich aber separat um den Upload zum Server kümmern. Da meine Datei dann auch nicht mehr von auphonic kommt, kann ich in WP nicht dessen paar Daten übernehmen und müsste den Blogpost dadurch auf andere Weise generieren. wie gesagt, ich schau mal.
Ich habe mir auch gerade das Release-Video noch mal angeschaut und ein wenig in US5 rumprobiert. So ganz erschließt sich mir noch nicht, was in welcher Reihenfolge sinnvoll ist.
Wann sollte ich die Tracks normalisieren? Nach dem „Reinladen“ / Aufnehmen? Über den Mixing-Pipeline-Workflow?
Das Gleiche bei den Dynamics – wann ist es sinnvoll, also in welchem Schritt der Produktion?
Reicht es, wenn ich die geschnittenen (und sonst unbehandelten) Spuren am Ende einmal durch die Mixing Pipeline jage? Und dafür aber im Vorfeld mit unterschiedlich klingenden Spuren schneiden muss?
Vielleicht denke ich auch gerade zu kompliziert, aber irgendwie habe ich für mich gerade den Eindruck, dass ich an mehreren Stellen gerade normalisieren, equalizen und angleichen kann und am Ende auch noch was automatisch passiert.
Ich bin jetzt keine Experte für alle Varianten, aber hier ist was ich mache:
Aufnahme stoppen
Prepare all Tracks for Editing
Bei Double Endern: Lokale Spur des Gastes synchron einfügen, Originalspur muten
Alle Sprachspuren (nicht das Soundboard) auf -23 LUFS normalisieren über Rechtsklick
Effekte EQ und Ultraschall Dynamics für jede Spur aktivieren
Effekt „LUFS Loudness“ auf der Masterspur aktivieren
Jetzt schneide ich fröhlich die Folge zurecht
Exportieren der Datei als 112 kbps mp3 mono (das ist Geschmackssache, hier kannst du auch 192 kbps stereo machen, wenn Deine Folge CD Qualität haben soll, dann sind die Dateien dementsprechend größer)
Metadaten, Chapter marks, Cover etc über den Assistenten einfügen.
fertig.
Wenn ich Auphonic nutze (was ich bei schwierigeren Episoden mit mehr Nebengeräuschen etc. mache), dann mache ich nur EQ auf die Spuren und normalisiere, damit das im Schnitt angenehmer ist. Das gesamte Levelling, Crossgate und so lasse ich von Auphonic machen.
Das ist nur mein Workflow, ich bin mir sicher, da gibt es viele andere individuelle Lösungen.
Danke Dir – so in etwa habe ich das auch immer gemacht, aber mit dem neuen Workflow „Automated Mixing Pipeline“ wird ja dann noch mal normalisiert und EQt – ist das nicht etwas viel?
Warum nochmal? Es gibt nur eine Normalisierung auf -23 LUFS, und EQ spielen gar keine Rolle.
Grundsätzlich würd eich wie oben von @Joram beschreiben dazu raten, den AMP-Workflow schon vor dem Schnitt einzustellen - dann hat man immer schon den richtigen, finalen Klang auf den Ohren.
Dazu geht man wirklich nur nach Prepare... die Punkt im AMP-Workflow durch und macht sich dann keine weiteren Gedanken mehr.
Danke Dir – ich glaube, was für mich den Knoten aufgelöst hätte im Eigenstudium, wäre, wenn der Workflow-Eintrag ziemlich am Beginn der Auflistung in der Prepare-Sektion gestanden hätte. So steht es etwas für sich und in der Logik „von oben nach unten durcharbeiten“ hätte ich ihn früher erwartet.
Ja, guter Hinweis. Grundsätzlich ist halt die Workflows-Sektion generisch gedacht - da könnten auch andere Einträge kommen, dir gar nichts mit Schnitt zu tun haben.
Unter „Prepare --> Items“ finden sich Normalize und Loudness auch schon, daher wusste ich nicht, ob das dann in der AMP redundant ist oder ergänzend. Vielleicht ist die Bezeichnung mit „Workflow“ auch nicht ganz treffend, denn das ganze Menü ist ja der Workflow und wenn die AMP am Anfang von „Prepare“ empfohlen ist, wäre vielleicht zu überlegen, sie auch direkt als Eintrag da zu platzieren. Workflow-Eintrag als „Toolbox“-Sammelkisten-Idee klingt charmant, je voller die wird, desto schwieriger wird es aber vermutlich, die Einträge logisch im tatsächlichen Workflow einzuordnen.
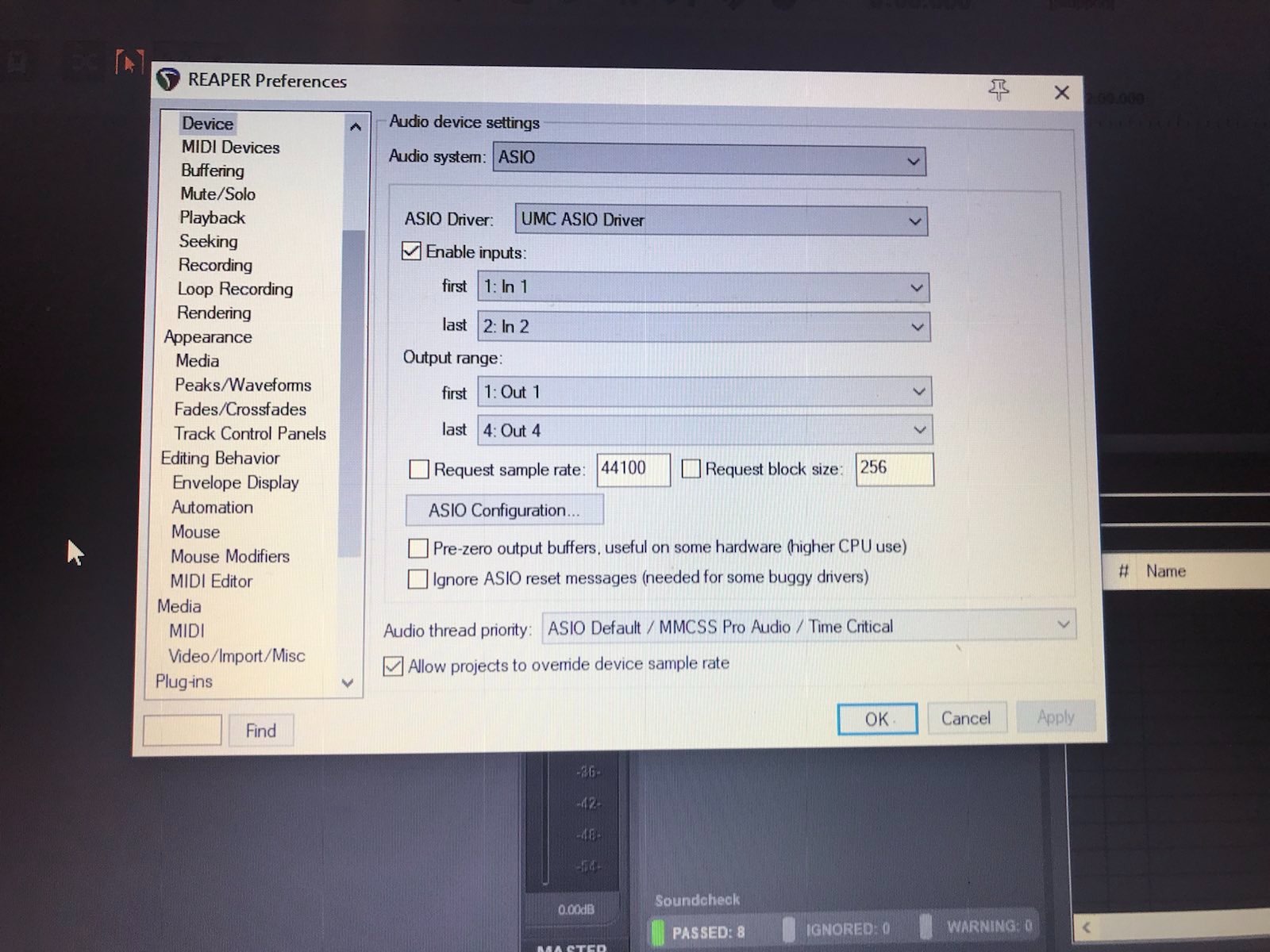
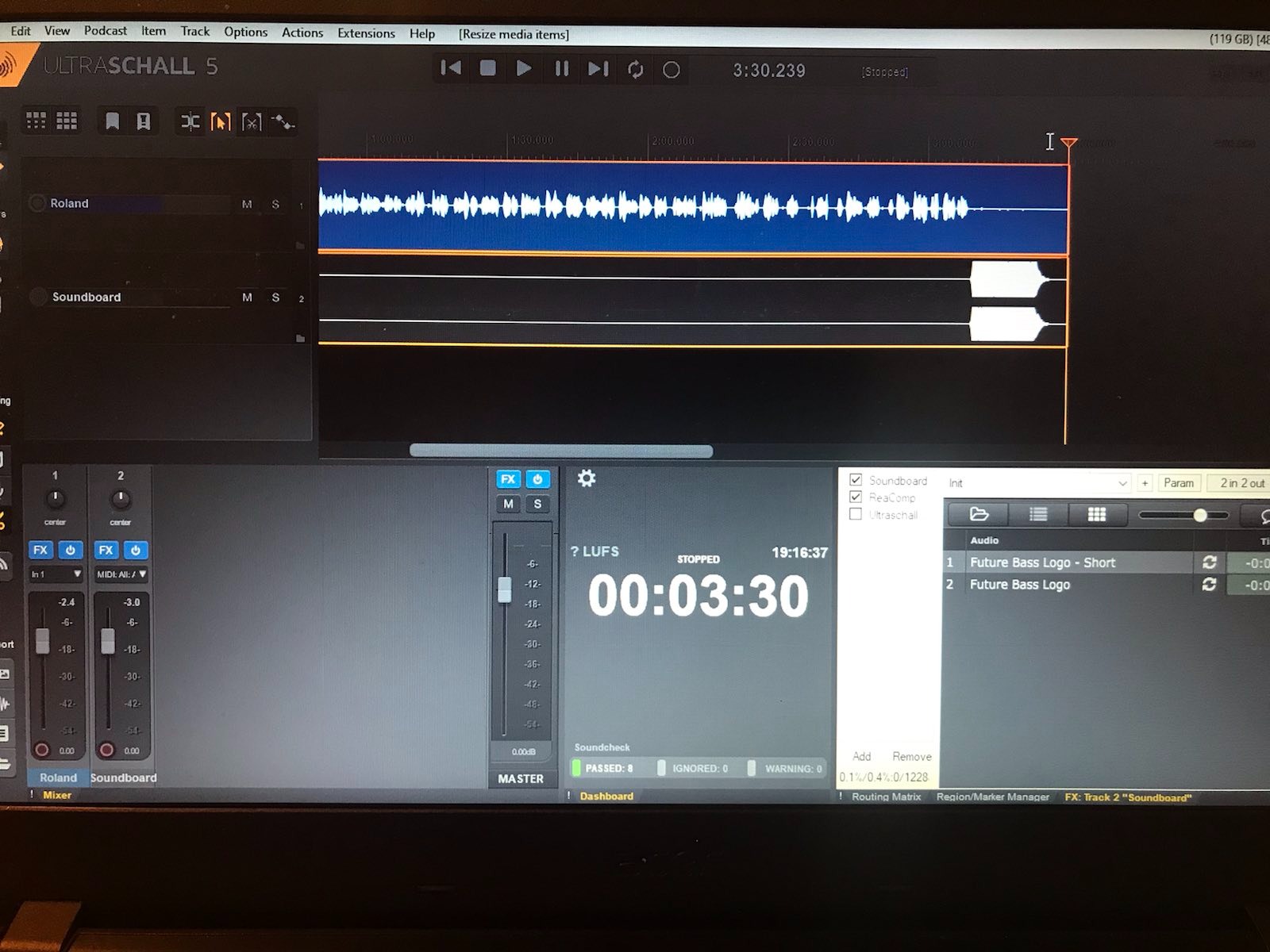
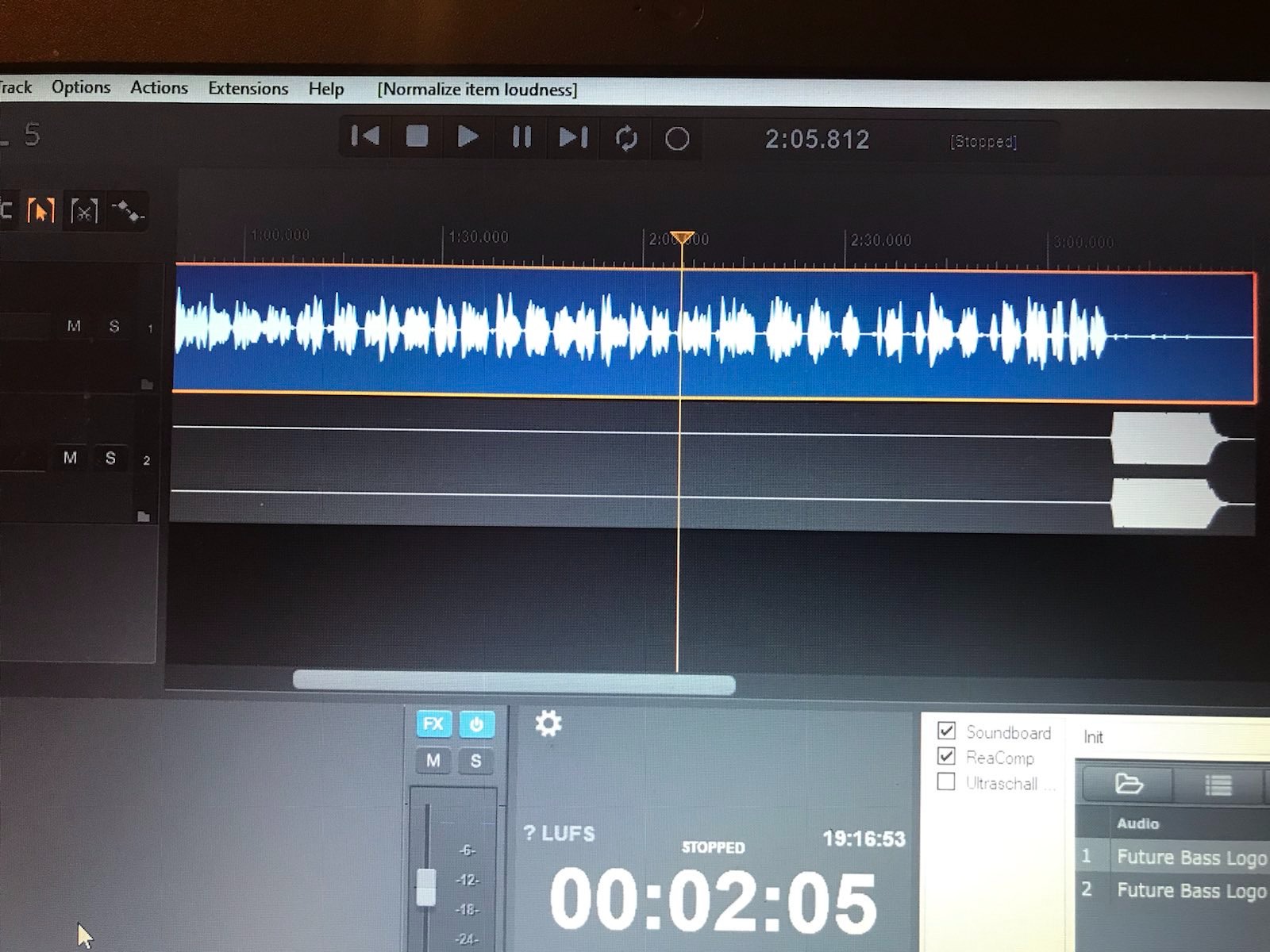
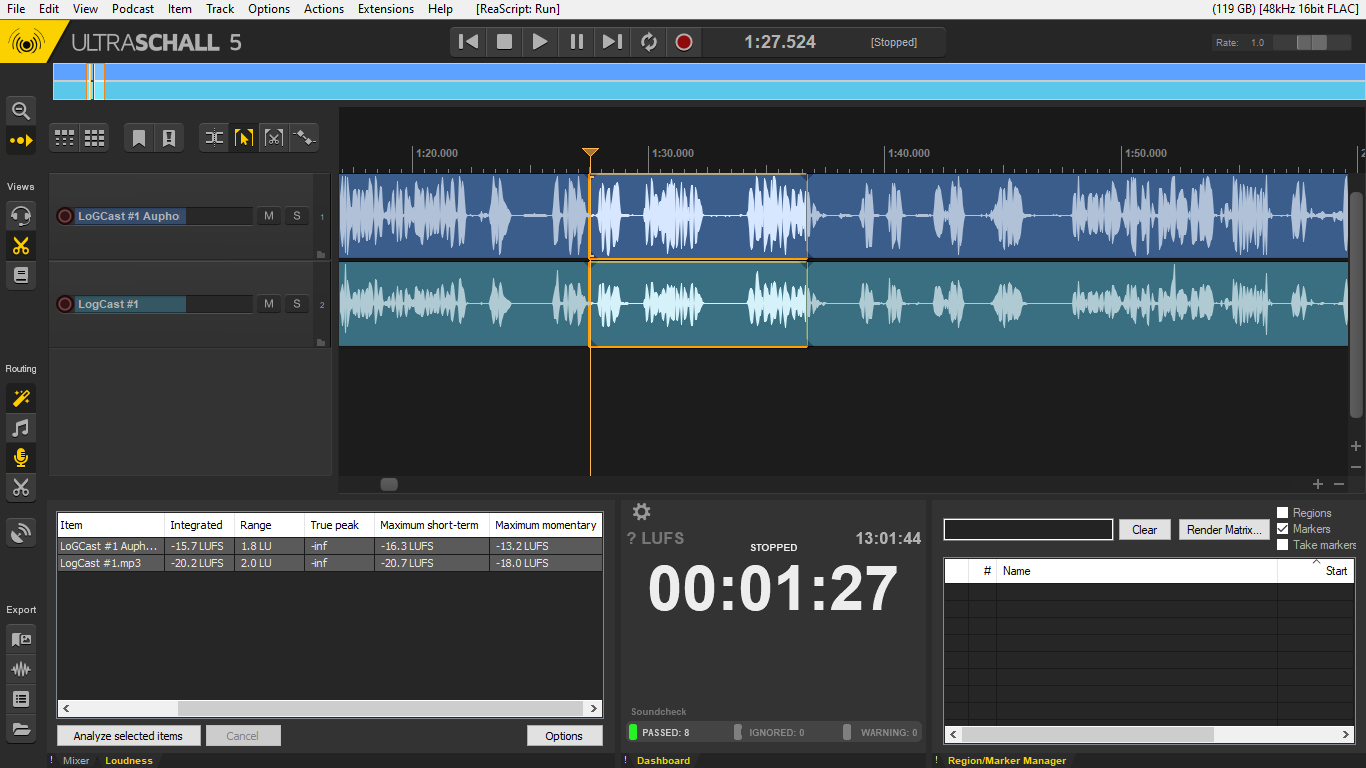
ich würde mich da als Einsteiger (sorry sollten es dumme Fragen sein ) gerne mit ein paar Fragen anschließen. Im Prinzip wende ich den Workflow wie @Joram beschrieben an jedoch irritieren mich da einige Dinge. Zum einen ändert sich in meinem Fall die Spurhöhe nach dem Normalisieren nicht so wie ich mir das vorgestellt habe (zumindest bei weitem nicht wie in den Praxisvideos von @rstockm) . Weiters beschäftigt mich die Frage wie ich Einspieler aus dem Soundboard, welches ich auf 70% einspiele, auf die gleiche Laustärke die der gesprochenen Spur angleichen kann. In meinem Fall verwende ich ein Inro der Seite AudioJungle. Diese ist natürich wesentlich lauter (-9dB) und erhöht si
ch nach dem Mastering nochmal. Das Ganze mit US5, UMC204HD mit ASIO und einem DT297. Um es zu verdeutlichen hänge ich ein paar Bilder an. lg Roland
Edit: noch ein Bild mit dem Vergleich zu Auphonic. Hier wird mein Problem nochmal deutlich sichtbar!
Am Ende sollten Auphonic und Studio Link Mastering die gleiche Lautstärke produzieren, wenn du alles wie oben beschrieben machst (Dynamics auf jeder Spur und Mastering auf der Master Spur). Ob die Waveform da anders aussieht ist zweitrangig, wichtig ist, ob der Lautstärke Messer da unten in der Mitte im grünen Bereich läuft.
Den benutze ich auch um mein Soundboard einzustellen. Ich drehe einfach manuell (bei aktiver Effektkette auch im Master) die Lautstärke der Spur oder Items so, dass der Lautstärke Messer grün zeigt und sich beim Abhören alles fein anhört. Da gibt es keinen Automatismus bei mir, ich mach das optisch und nach Gehör.
genau so mache ich es. Genau genommen verändere ich nach der Aufnahme nichts und bewege mich anschließend immer im grünen Bereich (so um die -16,2). Jedoch fallen die Unterschiede doch recht deutlich aus. Natürlich weiß ich als Leihe nicht ob das ein Fehler meinerseits ist und daher die Frage.
 ) gerne mit ein paar Fragen anschließen. Im Prinzip wende ich den Workflow wie
) gerne mit ein paar Fragen anschließen. Im Prinzip wende ich den Workflow wie