ich arbeite gerade an einem Projekt und würde super gerne euer Feedback dazu hören.
Es geht um eine Suchmaschine für Podcasts, die nicht nur Titel und Beschreibung durchsucht, sondern auch die Transkripte. So könnten Nutzer:innen auch Inhalte finden, die im Podcast erwähnt, aber nicht in der Beschreibung genannt sind.
Als Ergebnis gäbe es z. B.:
ein kurzes Zitat aus dem Transkript mit Zeitstempel,
einen Link zur Episode,
aber kein vollständiger Zugriff auf das Transkript, es sei denn, die Podcaster:innen geben diesen explizit frei.
Die Idee wäre z. B. hilfreich, um relevante Erwähnungen oder Themen in Podcasts leichter auffindbar zu machen.
Hättet ihr Bedenken, was die Nutzung eurer Inhalte betrifft (z. B. automatische Transkription)?
Was müsste so ein Tool aus eurer Sicht können, um echten Mehrwert zu bieten?
Danke für deine Antwort. Posuma finde ich auch eine spannendes Projekt
Meine Umsetzung basiert auf einem automatischen Prozess, der die RSS-Feeds der Podcasts in regelmäßigen Abständen nach neuen Folgen durchsucht und diese dann transkribiert. Die Transkripte könnten dann per Stichwortsuche + Filter (nach Kategorie, Podcast, Erscheinungsdatum, etc.) durchsucht werden.
DerJuergen
(Schmerzenssache | Ach? Triumvirat für historisch inspirierte Humorvermittlung)
4
Wie planst du das Ganze zu skalieren? Kenne ein ähnliches (internes) Projekt von einer Hochschule, aber der Aufwand im Hintergrund ist enorm. Der Nutzen auf der anderen Seite allerdings auch.
Ich denke für geschichtspodcasts.de seit einer Weile über etwas Ähnliches nach: eine überschaubare Menge an Podcasts, bei denen neue Episoden automatsich transkribiert werden – und dann werden daraus nach einem festen Regelsatz Themen-Schlagworte abgeleitet. Die wiederum lassen sich dann super für Filter und Navigation verwenden (das funktioniert heute schon, allerdings mit komplett manuell gepflegten Schlagworten). So stelle ich mir das vor, aber ich kam noch nicht dazu, das mal auf Umsetzbarkeit zu prüfen. Lohnt es sich wohl, dass wir uns dazu mal austauschen?
Die Idee finde ich grundsätzlich erstmal nicht verkehrt. Imho sollte deine Suchmaschine bereits bestehende Transkripte, die im Feed mit ausgeliefert werden, bevorzugen. Was mir auch noch wichtig wäre: Wenn ein Podcast eine Lizenz mitliefert, also etwa CC-BY-SA, muss das ebenfalls berücksichtigt werden. Und natürlich ist aus meiner Sicht eine Monetarisierung ausgeschlossen: Kostenlos angebotener Content Dritter sollte keine Einnahmequelle sein.
In meinem Prototyp hatte ich mich erstmal gegen die Einbeziehung bestehende Transkripte entschieden, hauptsächlich um es einfacher zu halten und aufgrund der unterschiedlichen Qualität. Schaue mir das Ganze aber nochmal an.
Der Hinweis zu den Lizenzen ist sehr gut. Viele Podcasts geben ja keine explizite Lizenz an. Mein aktueller Gedanke ist daher: Podcasts werden standardmäßig in der Suche berücksichtigt, aber Podcaster:innen können per Opt-out widersprechen. Zusätzlich könnten sie per Opt-in zustimmen, dass auch das vollständige Transkript angezeigt werden darf. Was hältst du von dem Plan?
Eine direkte Monetarisierung von frei zugänglichem Content Dritter kommt für mich nicht infrage. Die Frage, wie sich ein solches Projekt langfristig tragen kann, bleibt natürlich offen. Ich möchte aber nicht ausschließen, dass es künftig Weiterentwicklungen geben könnte, die monetarisiert werden. Dabei ginge es dann um Angebote, die auf einem eigenständigen Mehrwert basieren und nicht unmittelbar aus dem Content Dritter.
Uh, die Sache mit der Lizenz ist schwierig, denn wenn es nicht angegeben ist, gilt „im Zweifel alle Rechte vorbehalten“, sprich eigentlich sind die dann offlimits. In sofern finde ich Deinen Ansatz mit dem Verzicht der Monetarisierung okay.
Wenn ich noch anmerken darf: Eine Verlinkung mit dem originalen RSS-Feed sollte Pflicht sein. Ich habe weiterhin Bauchschmerzen mit der Transskribierung auf Deiner Seite … aber so richtig festmachen kann ich das nicht, so richtig verbieten kann es Dir niemand, denke ich.
Aus dem Grund der fehlenden Lizenz würde ich auch keine Transkripte ohne explizite Erlaubnis anzeigen. Und in der Suche nur ein kurzes Zitat der Stelle und den Zeitstempel.
Ich schätze es so ein, dass ich den Podcaster:innen so helfe ihre Inhalte sichtbarer zu machen und besser von Nutzern auf der Suche nach neuen Formaten entdeckt werden können.
Dementsprechend auch Verlinkung des originalen RSS-Feeds (danke für den Hinweis!), aber auch Verlinkung zur Webseite des Podcasts, und auch Link zur Episode direkt (wenn im Feed angegeben).
Ich kenne verschiedene Lösungen, die Podcasts bereits flächendeckend transkribieren und sowohl die Suche darauf als auch die vollständigen Transkripte anbieten. Diese sind aber alle kostenpflichtig.
Ich habe mal ein paar use cases ausprobiert und hätte folgenden Senf abzugeben:
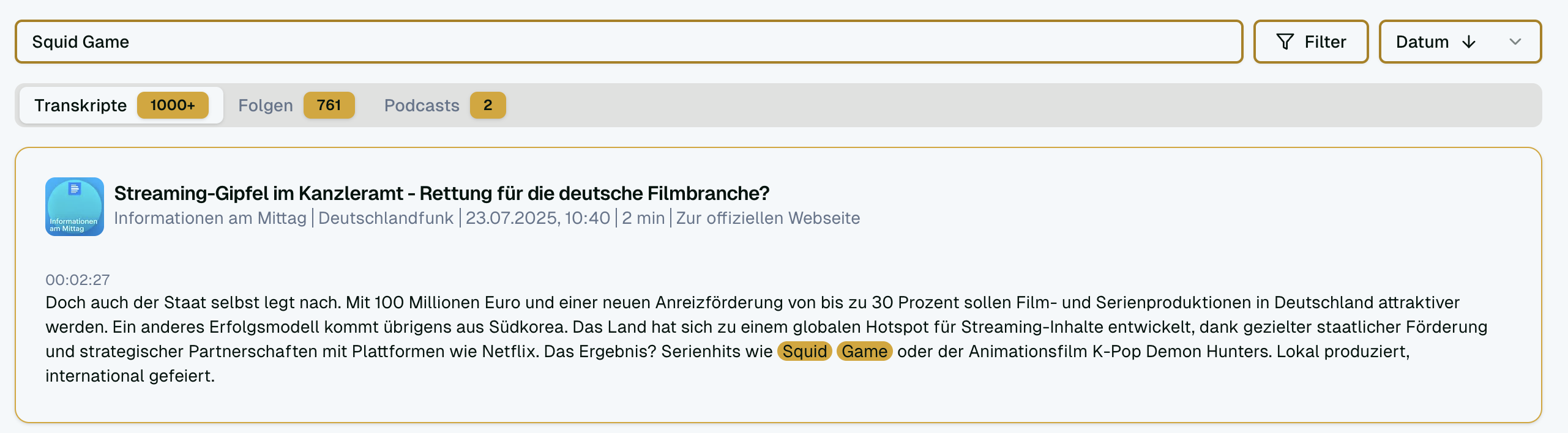
Die Seite finde ich sehr schön aufgeräumt und ansprechend, gefällt mir gut. Die Suchergebnisse sind auch schon echt hilfreich, ich habe jedenfalls immer gefunden, worauf ich hinauswollte.
Bei der Darstellung der Ergebnisse unter „Folgen“ würde ich noch vorschlagen, die Ergebnisse ähnlich kurz darzustellen wie unter „Transkripte“, so dass man die auch ausklappen kann. Die Einträge nehmen teilweise sehr viel Platz ein, da ist die Ergebnisliste „Transkripte“ deutlich übersichtlicher.
Was die grundsätzlich Frage nach den Transkripten angeht, schließe ich mich Jörn an: Ich denke, Transkripte, die schon vorhanden sind, sollten bevorzugt und nur dann eigene erstellt werden, wenn es noch keine gibt. Erstens halte ich das andernfalls für Energieverschwendung und zweitens geben sich einige Podcaster:innen extra Mühe, ihre Transkripte zu prüfen und z.B. Fachbegriffe zu korrigieren (also nicht ich, aber soll ja vorkommen :D). Der Aufwand läuft hier völlig ins Leere, wenn trotzdem noch ein neues Transkript erstellt wird. Das halte ich jedenfalls für den größeren Verlust, als das ein oder andere schlechte Transkript einzulesen.
Insgesamt aber cooles Projekt, eine gute Transkript-Suche habe ich schon länger gesucht!
Danke dir für das tolle Feedback! Es freut mich sehr, dass dir die Seite gefällt und die Suche für dich gut funktioniert.
Ich stimme dir voll zu, dass die Ergebnisse bei den Folgen besser dargestellt werden können. Und danke auch für deine Meinung zur Verwendung der bestehenden Transkripte. Werde versuchen diese in PodRadar zu nutzen.
Kurzes Update:
PodRadar nutzt nun Transkripte, wenn diese im RSS-Feed verlinkt werden Unterstützt werden aktuell die Formate VTT und SRT, andere Formate folgen leider keinem Standard und lassen sich daher nicht zuverlässig auslesen. Mit den beiden unterstützten Formaten sind aber bereits rund 90% der bereitgestellten Transkripte abgedeckt.
Auch die Suchergebnisse für Episoden und Podcasts sind jetzt übersichtlicher.
Ich plane gerade einen Bereich, in dem Podcaster:innen die Transkripte der eigenen Podcasts herunterladen und auch freischalten können, dass den Nutzern die vollständigen Transkripte zur Verfügung gestellt werden, um die Inhalte leichter auffindbar zu machen. Was haltet ihr davon? Welche Funktionen würdet ihr euch noch wünschen?