Es ist zwar schon etwas her, aber @rstockm hatte angeregt, dass man das ja auch gleich automatisieren kann.
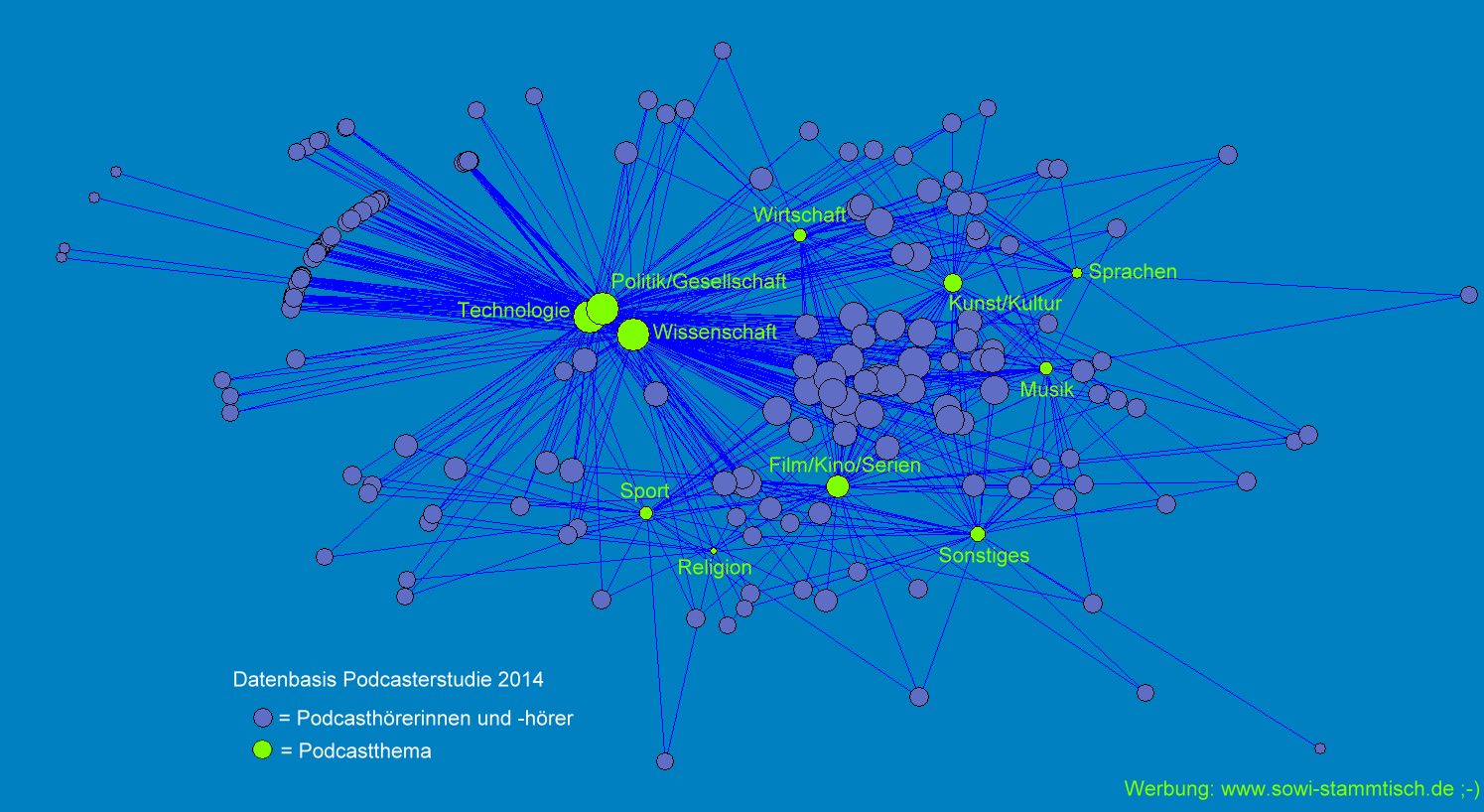
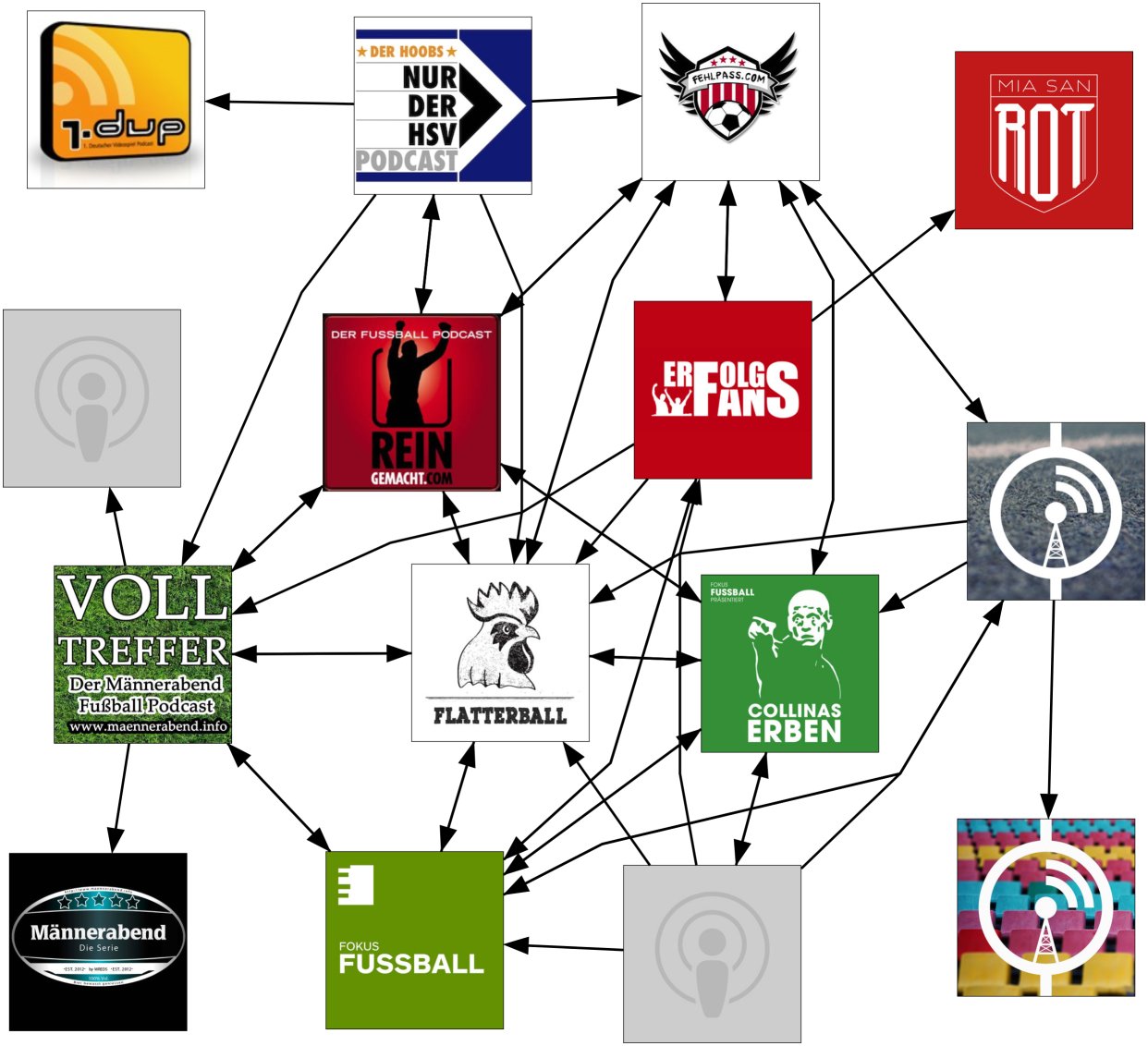
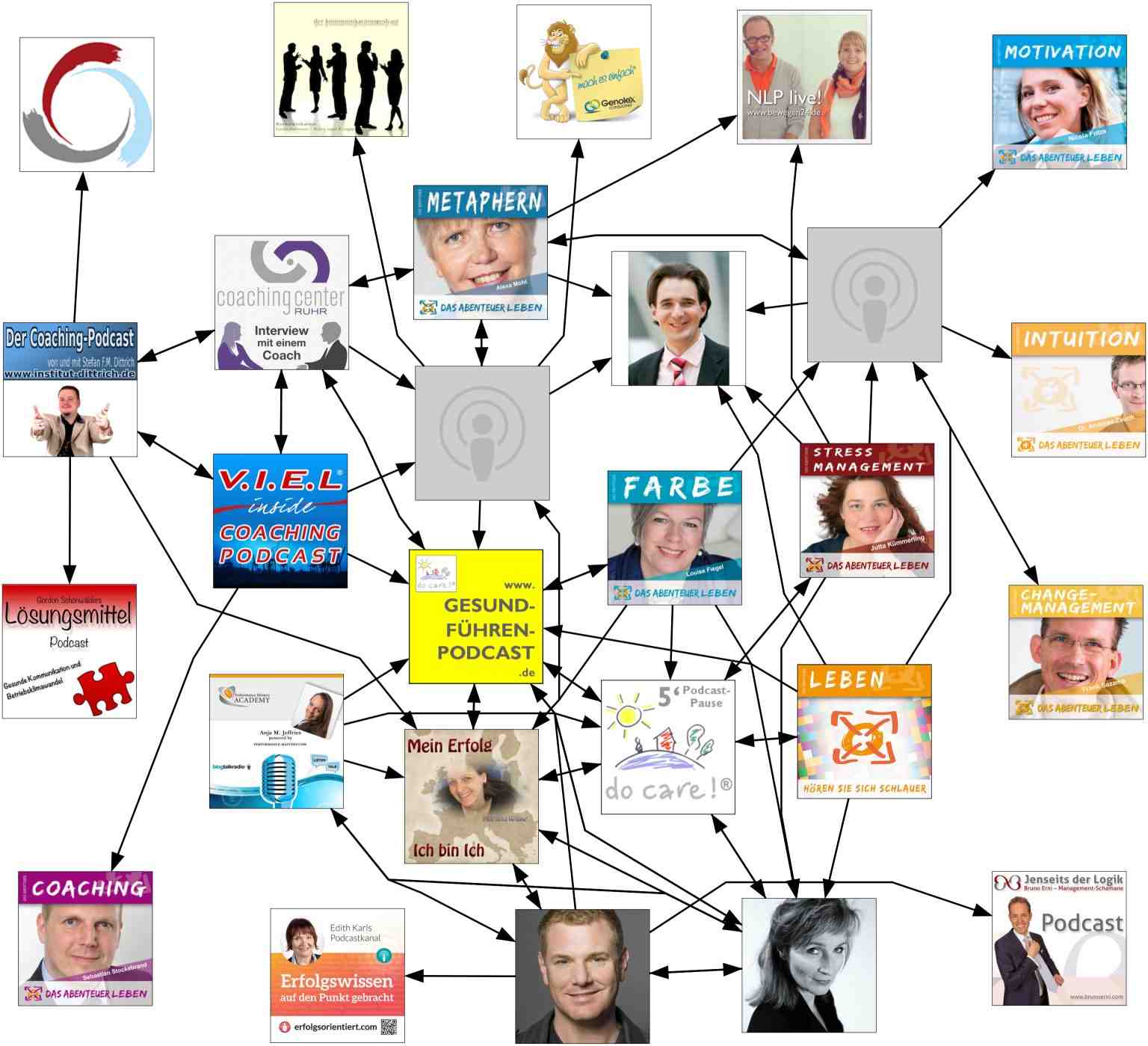
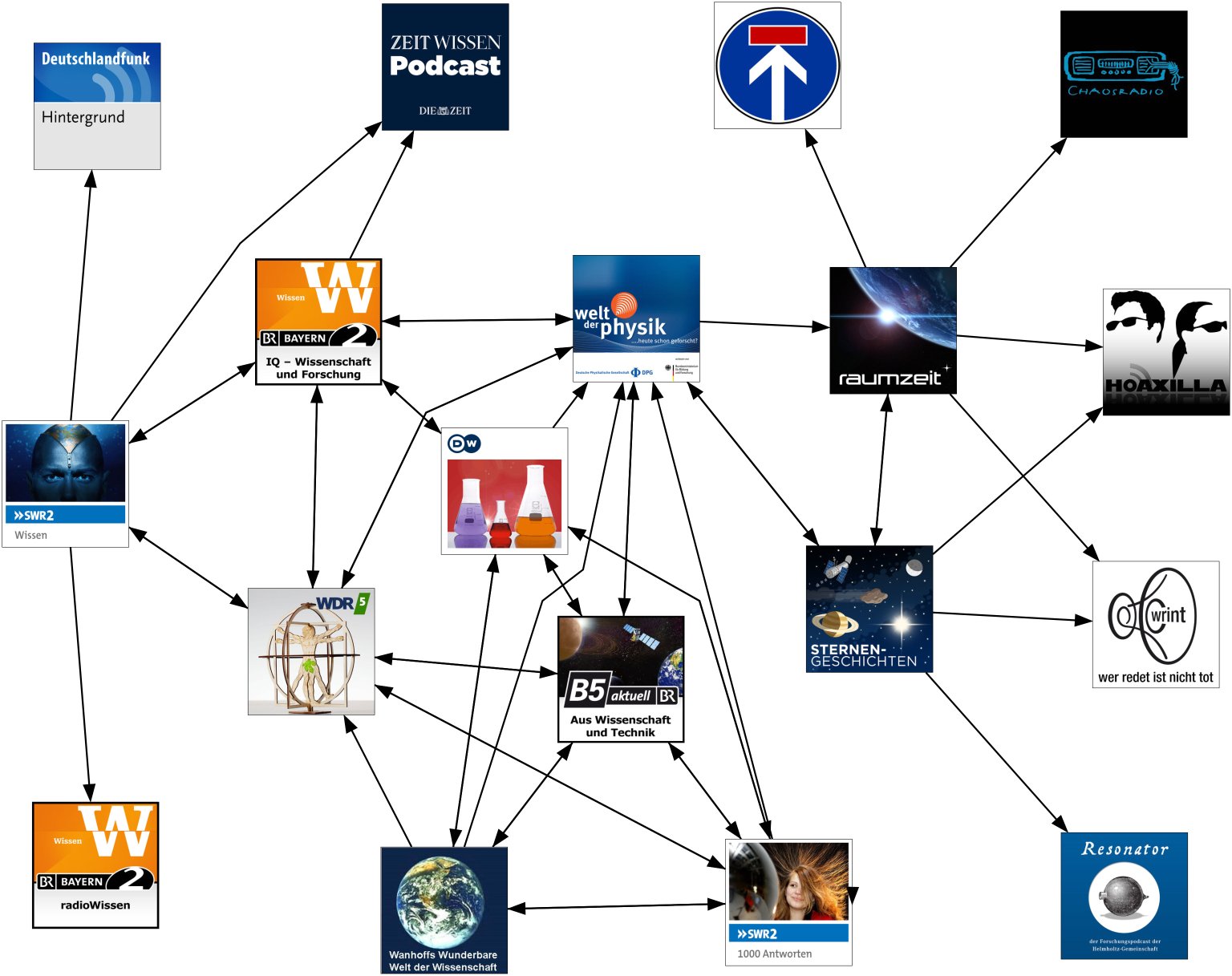
Ich habe die Informationen aus den Podcast-Seiten von iTunes übernommen- hier sind bei jedem Podcast fünf weitere Podcasts angegeben, die Hörende dieses Podcasts auch hören. Und man kriegt auch gleich Bilder zu jedem Podcast.
Diese gerichteten Graphen lasse ich für alle Podcasts aus einer (recht zufälligen) Liste sammeln und dann bis in eine bestimmte Tiefe mit beispielsweise Neato von GraphViz automatisiert visualisieren.
Bezogen auf den Startpodcast werden die umliegenden Podcasts durch die bestehenden Kanten im Graph gruppiert und näher oder weiter von einander gestellt. Natürlich könnte man die maximale Kantenlänge vom Startpodcast vergrößern, oder mehrere Podcasts als Start-Knoten verwenden- das wurde aber ziemlich schnell unübersichtlich oder brauchte mehr Speicher als mein virtueller Server gerade hatte.
Aber auch so kann man ein paar interessante Schlüsse ziehen: Damals konnte man auch unter den Hörenden einen gewissen Wissenschafts-Podcast-Cluster erkennen- zumindest zwischen den Podcasts die vernetzend tätig sind, und gegenseitig auf interessante Themen hinweisen. (Ergo: Die Zuhörerschaft nimmt Empfehlungen sehr positiv auf!)
Noch stärker fiel der Geocaching-Cluster auf- hier gab es damals eine ganz eingeschworene Gemeinschaft, die sehr themenbezogen die Podcasts abonnieren.
Natürlich muss man diese Ergebnisse sehr mit Vorsicht betrachten- immerhin gibt es auf iTunes keine Zahlen, es geht nur um die Nutzer von iTunes, und es gibt auch immer nur höchstens fünf Kanten pro Knoten. Dafür gibt es diese Statistik ziemlich aktuell und für alle Podcasts, die auf iTunes gelistet sind.
Die Graphen waren für mich ein kleines Experiment, ich würde mich sehr freuen, wenn das jemand weiter verfolgt, oder einen umfassenderen Dienst dafür zur Verfügung stellt. Ich lasse das Skript gerade neu durchlaufen und werde heute abend eine aktualisierte Fassung (mit mehr Podcasts) online stellen.
Update: Auf http://modellansatz.de/graphs/ gibt es jetzt aktualisierte Graphen, und ich habe die Liste der Podcasts, für die die Graphen erzeugt wurden etwas vergrößert.


{kind=link}
{kind=link}
{kind=link}
{kind=link}