Zunächst vielen herzlichen Dank für die Kommmentare …
Wenn ich geahnt das hätte … dann hätte ich vor Abschluss meines
Sprecher-Diploms besser nichts gepostet :-). Es ging mir ums Technische, hier
vornehmlich um den WUMMS, diesen komprimierten Laserstrahl am Ohr.
Andererseits habe nun auch ein paar erste Eindrücke zur Rezeption meiner stimmlichen Darbietung erhalten und bin dafür nicht undankbar 
Vielleicht erst einmal dazu etwas:
Die Grenzen zwischen Nuscheln und unsauberer Aussprache sind fließend.
Ich glaube aber, dass ich eher NICHT durch die Nase zu sprechen versuche,
es ist tatsächlich so, dass ich manchmal einfach ein paar Silben zu schnell
spreche, weil es so eine Sache ist mit Atmung, Intonation, Geschwindigkeit.
Vor allem mit Atmung - ich glaube es liegt vor allem daran, dass ich dann
unsauber (undeutlich) werde, damit’s noch in den Slot vor dem Luftholen passt.
Dazu kommt noch eine wahrscheinlich naturgegebene unsaubere Aussprache - die ich
mir tatsächlich abtrainieren muss.
Da hilft es, sich möglichst oft auch selbst zu hören, womit ich nun gerade anfange. Und hilfreich ist zudem, wenn es aufmerksame Fremdhörer gibt, die einen persönlich gar nicht kennen und eine “freie” Wahrnehmung haben.
(Also, Ihr zum Beispiel).
Trotz der von Euch erwähnten Unzulänglichkeiten habe ich Hoffnung, dass es mit mir noch mal was wird! Wenn auch nicht mit Texten wie diesen… 
Ich bin eher ein “Ohrflüsterer” mit leisen Nuancen. Ich könnte von daher kaum jemals Nachrichtensprecher oder Offline-Sprecher für Sachtexte werden - meine Art zu Sprechen plus Stimmfarbe - das passt nicht. Aus MEINER Sicht. Daher empfinde ich den aktuellen Text auch als eher ungeeignet für mich.
Ich habe ihn nur aus technischen Erwägungen gewählt, der Vergleichbarkeit halber, da der Sprecher des Originals, Patrick Imhof (Sprecher und Schauspieler), im Vergeich zu anderen auf Vorleser .net eine ähnliche “WUMME” erreicht, wie ich sie gerne hätte. Er ist Profi, er hat Druck auf der Stimme (im Gegensatz zu mir), aber ZUSÄTZLICH hat er eine ordentliche Kompression/Verstärkung drin.
Um diese ging es mir.
Sie wird mir natürlich wenig nutzen, wenn ich nuschle, Silben verschlucke, nicht für einen anonsten schalldichten Raum bei der Aufnahme sorge, während der Aufnahme irgendwo anstoße oder ein “s” zischen lasse… usw.
Dennoch habe ich gedacht, ich frage mal, ob und wie man ggf. mit Ultraschall/Reaper die nunmehr oft zitierte Wumme hinbekommt.
Den Rest, so hoffe ich - auch gerade auch nach den Beurteilungen hier - bekomme ich mit der Zeit hin. Die Kommentare haben mir geholfen, ich danke Euch ausdrücklich dafür!
Ich hätte Patrick Imhoff übrigens natürlich namentlich erwähnen können, vielleicht auch
sollen @UliNobbe, hier ging es aber nur um eine technische Demonstration von ~50s, sodaß weder die künstlerische Darbietung noch der Inhalt relevant sein sollte. Zudem habe ich die Metadaten unverändert gelassen, die Quelle und Urheberschaft ist also weiterhin nachvollziebar. Und nach Abschluss
dieser Diskussion geht das File sowieso wieder vom Netz.
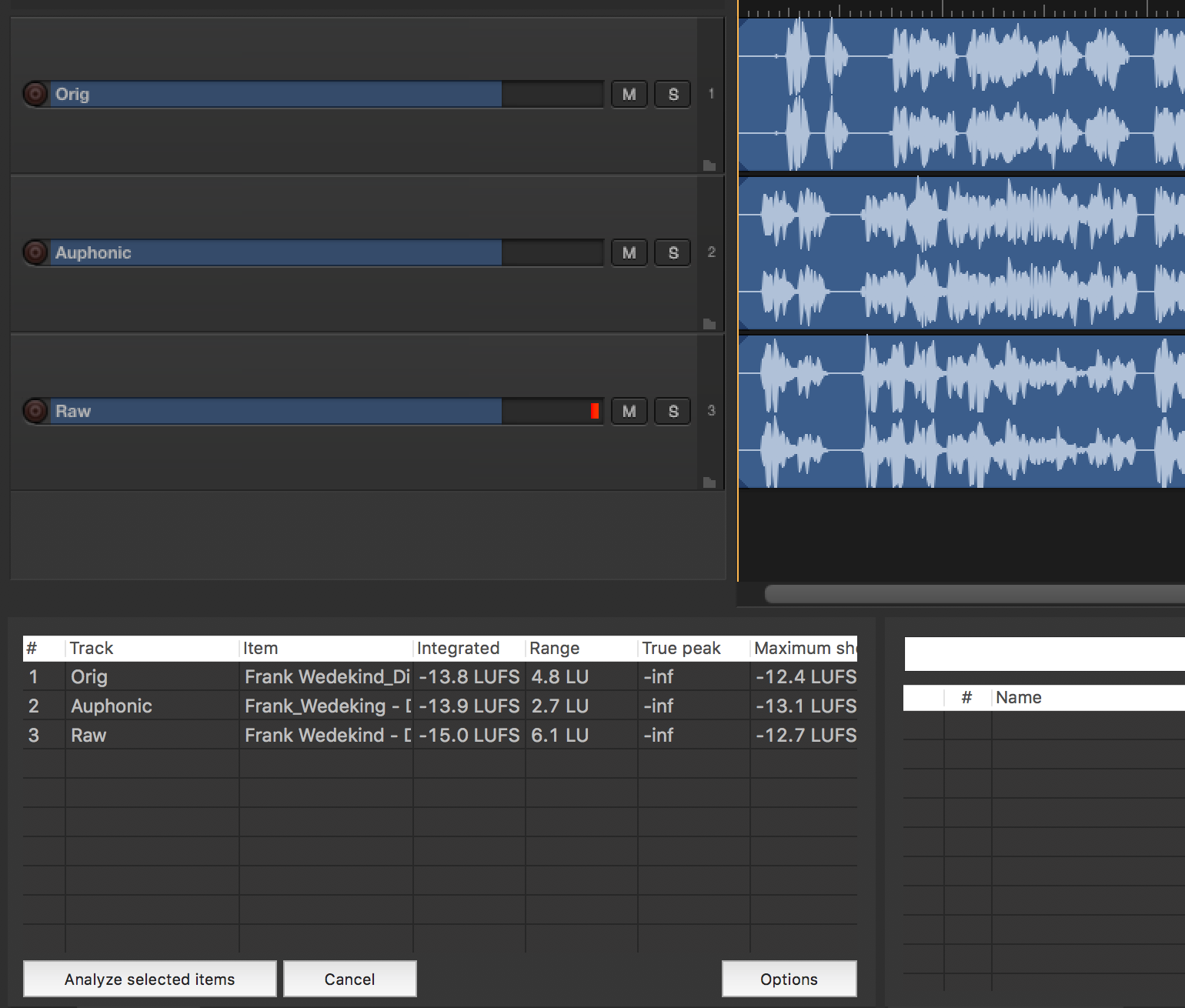
Zur Aufnahme:
Ich hatte sowohl mit RealEQ als auch Ultraschall Dynamics herumgespielt. Dies erklärt
den (offenkundig übereifrigen) Bass und sonstigen Schnöttelpröm.
Ich habe alles wieder herausgeschmissen, unter o.g. Link findet sich nun noch ein drittes File: RAW - ohne Plugins.
Identische Aufnahme, ohne Geschmacksverstärker, ohne Auphonic - splitternackt, wie aufgenommen!
Und es fehlt immmer noch: Der WUMMS …