Hm die ist nun mit -37 LUFS entschieden zu leise. Normalerweise sollte ein Punkt auf der Skala nicht so einen riesen Unterschied beim Gain machen. Was mir gerade auch auffällt: warum hast du die alten Aufnahmen eigentlich in Stereo vorliegen? Das ergibt per se schon immer weniger “Punch” als Mono, und unsere Stimme ist ja nun mal Mono.
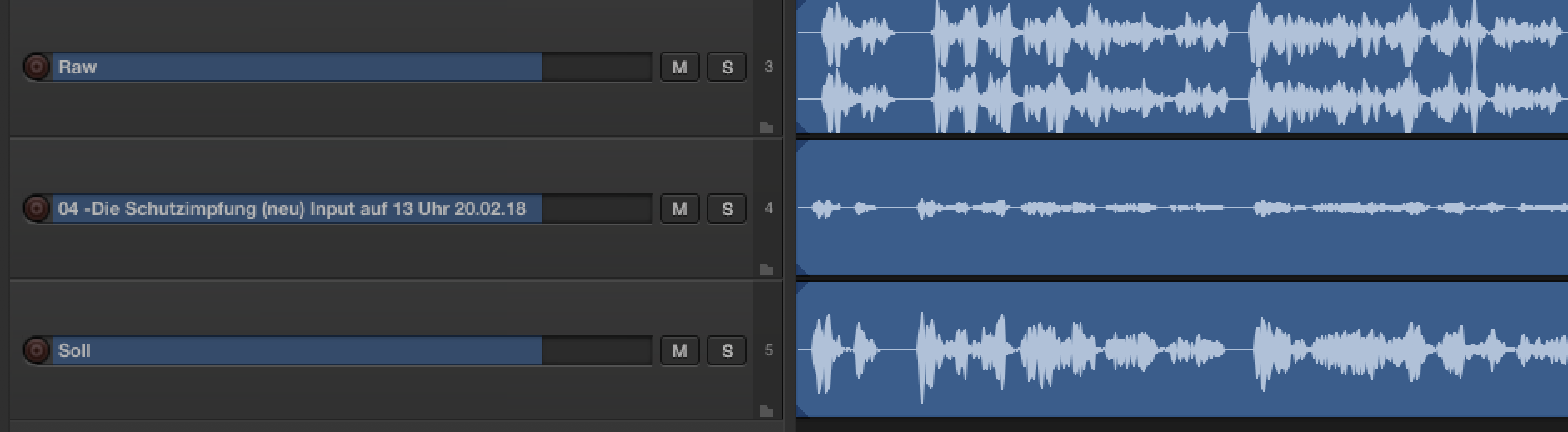
Hier mal deine alte, zu laute Stereo-Aufnahme unten, die sehr leise neue in der Mitte und unten wie es aussehen sollte: die liegt bei -23 LUFS da hat man dann noch genug Spielraum.
Was spricht dagegen, eine Aufnahme mit reichlich Headroom (und 24bit  ) aufnehmen und anschließend “normalisieren” - und auf der Basis dann zu entscheiden?
) aufnehmen und anschließend “normalisieren” - und auf der Basis dann zu entscheiden?
(Ich kann erst heute abend genauer in die Datei 'reinschauen)
Bye
Volker
Nun, in seiner neuen Aufnahme sind rund 70% der Bits komplett ungenutzt. Das ist für den Signal-Rauschabstand eher nicht so dolle, da helfen dann auch die 24Bit nur bedingt weiter. So -12dB als Target mit Spitzen bis -6dB finde ich für menschliche Stimme schon einen sehr robuste, konservativen Wert.
Als Headroom reicht im Normalfall -6dB. Wenn Du also nicht über -6dB kommst(mal laut ins Mikro reden und schaun, was der Pegel sagt), dann biste im Normalfall auf der sicheren Seite.
1 „Gefällt mir“
Auch wenn er sehr zaghaft ausgesteuert hat (-18dB), so sind das nur 3 Bits die er ungenutzt lässt (6dB/bit)!
Es sind nicht die wenigen ungenutzten Bits die das Rauschen erzeugen sondern die unintuitive Tatsache dass Vorverstärker bei geringer Verstärkung (auf den Eingang bezogen) mehr Rauschen erzeugen als bei hoher Verstärkung. Das fällt aber eher bei sehr rauschfreien (z.B. dem NT-1A) oder sehr unempfindlichen (dynamischen) Mikros in’s Gewicht.
Öhm. Das ist im Prinzip richtig, aber dann doch nur die halbe Wahrheit, da die Bit ja „mehr wert“ sind als die anderen?
Mal grafisch argumentiert: nehmen wir mal an, seine Bittiefe sei so gering, dass er überhaupt nur 100 Stufen auflösen würde (ca. 7 Bit), dann würde er davon so wie seine Kurve aussieht nur die Werte 0 bis ca. 25 überhaupt nutzen - alle Werte von 26 bis 100 lässt er ungenutzt liegen. Sprich: 75% seiner Datenmenge sind „ungenutzt“.
Wo in den Menüs versteckt sich dieses Analyse-Tool im Screenshot?
Einmal hatte ich es bei mir auf dem Schirm … seitdem ist es forever gone…
So, ich habe jetzt nochmal eine Aufnahme gemacht, (Nr. 5 )
https://app.box.com/s/ry1pe44uap0lwxv1xti9nqv7wqaikpyy
Bin beim MIC-Gain wieder zurück auf Reglerstellung 14 Uhr - ich denke, das sollte ungefähr OK gehen. Wieder alles auf 0dB und nackig (o. Plugins), aber ich habe ja jetzt gelernt, dass ich nun auch auf LUFS achten soll, das man offenbar erst erkennt, wenn man eine Probeaufnahme gemacht hat und dann nachmisst. Das habe ich hier nicht gemacht, weil ich
den Menüeintrag nicht mehr finde …
Zur Frage: Die erwähnte _Stereo_aufnahme ist entstanden, weil die Voreinstellung beim Rendern auf Stereo steht und ich sie nicht auf Mono geändert hatte.
Auch wenn wir das vielleicht in einen Technikphilosophie-Bereich des Sendegate verschieben sollten, korrekte Nomenklatur ist wichtig ![]() . Bitte schmeiss meinen Beitrag einfach aus diesem Thread raus wenn unpassend.
. Bitte schmeiss meinen Beitrag einfach aus diesem Thread raus wenn unpassend.
Exakt, und daher gibt es ja auch diesen riesigen Unterschied von 16bit zu 24bit (was selbst bei sehr nachlässiger Aussteuerung „unhörbar“ bis „Düsenjet“ abdeckt). Obwohl es nur 50% mehr Daten sind.
Ich finde den Vergleich mit einem analogen Mischpult und dessen Ein- und Ausgängen (die bei einem Audiointerface natürlich nur noch auf wenigern Zentimetern der Platine als analoge Spannungen existieren) viel eingängiger:

25/100 entspricht ziemlich genau -12dB Aussteuer-Reserve, ein weiter oben empfohlener Wert ![]() In dem Fall des Analogmischpultes sind das die unteren beiden gelben LEDs. 75% der Amplitude sind ungenutzt, aber eigentlich gut eingepegelt.
In dem Fall des Analogmischpultes sind das die unteren beiden gelben LEDs. 75% der Amplitude sind ungenutzt, aber eigentlich gut eingepegelt.
Gewagte These. Ich lege ein Veto ein.
Das ankommende Mikrofonsignal ist ja nun immer gleich.
Mono heißt ja nichts anderes, dass die Kanäle „links“ und „rechts“ gleich sind = es keine Laufzeitunterschiede gibt. Das ankommende Signal wird also auf beiden Kanälen gleich aufgenommen.
Wo da plötzlich „weniger Punch“ als bei einer einspurigen Aufnahme herkommen soll, erschließt sich mir nicht.
Die Signalstärke wird ja nicht aufgeteilt und je Kanal abgeschwächt.
Vielmehr ist es so: 100% Pegel auf einer Spur: 100% Signal.
100% Pegel auf 2 Spuren: 100% Signal auf links und 100% Signal auf rechts.
Für eine Mono-Aufnahme reicht es nun, die Stereospur aufzuteilen und eine der Spuren zu löschen (und auf Center zu stellen). Der Effekt bleibt gleich; man spart sich nur Arbeitsschritte.
Würde man hingegen die Stereospur zur Monospur mischen, d.h. addieren, käme das einer Verdopplung des Pegels mit entsprechendem Clipping gleich.
Dass eine Aufnahme gleich in eine Monospur Ressourcen spart (und die Dateigröße des Podcasts ohne Qualitätsverlust deutlich reduziert), ist unbestritten. Nur hat das nichts mit Deiner These zu tun.
Auch ich empfehle bei Sprachaufnahmen gleich die Mono-Einstellung (streng genommen: Die Einspurigkeit). Audiophile Puristen hingegen empfehlen sogar die „doppelte“ Aufnahme mit Headroom und Spur-Addition, aber das ist der Sache letztlich nicht dienlich.
Wir würden den gleichen Tipp abgeben, aber unsere Argumente wären unterschiedlich. Deine Argumente halte ich für nicht zutreffend.
Nochmals: „Mehr Punch“ auf Monospuren? Nein, das kann ich nicht unterschreiben; ich fürchte, da leitest Du unseren Fragesteller in die Irre. Den wird er so auch nicht bekommen.
Ja ich lager das heute Abend mal aus, aber das sind wichtige Nerd-Diskussionen ![]()
Also: ich bin natürlich von echtem Stereo ausgegangen, nicht von einem 1:1 Signal rechts-links. Und bei echtem Stereo ist es durchaus so, dass ein Stereo-Signal im Schnitt 3 LUFS leiser ist als Mono. @auphonic hatte das mal auch in einem Blogpost beschrieben, finde ich aber gerade nicht.
Wenn das verwendete Mikro kein echtes Stereo aufzeichnet, ist es natürlich egal. Aber etwa bei XY-Mikro des Zoom H6 spielt das durchaus eine Rolle.
Und ich schreib sogar noch in den Threadtitel: A-N-F-Ä-N-G-ER-Frage… also irgendwas auf 5V-Level…und wir sind hier schon auf Starkstromniveau …
Aber wie auch andererorts üblich, bin ich natürlich selbst schuld.
Schließlich habe ich ja nach WUMME verlangt. Und die gibt’s nicht nur in dB, in LUF oder LUFFS,
sondern - absolut nachvollziehbar - nur unter Berücksichtigung der Amplitude, dabei Leistungsreserven
beachten und 3bit nicht mit 7bit verwechseln…


Ich lese interessiert mit. Vielleicht, so die Hoffnung, verstehe ich es ja in 3-6 Monaten besser 
Zunächst beantworte ich mir meine o.g. Frage mal selbst: Analyze items ruft man unter Erweiterungen / Loudness auf.
Für den einen oder anderen Anfänger zur Info.
2 „Gefällt mir“
Schalte den View mal auf Schnitt um, dann hast du ganz unten Links einen Reiter „Loudness“.
Die neue Aufnahme ist IMHO perfekt ausgesteuert für unsere Zwecke. Wenn es hier generell um Hörspiel-Qualität geht, würde ich ausnahmsweise auch die Aufnahme in 24 Bit empfehlen (für normale Gesprächspodcasts bleibe ich bei 16 Bit, wie hier schon hinlänglich diskutiert).
1 „Gefällt mir“
Und jetzt nochmal allgemein zum “Wumms”. Es wurde hier ja schon angesprochen: vielleicht ist zu viel Wumms gar nicht mal so wünschenswert. Wenn du eine sauber ausgesteuerte Aufnahme hast, die nicht rauscht (check) und die gut betont einsprichst (ausbaufähig, aber ich finde auch hier hast du schon ein ordentliches Niveau) und dann das durch einen Leveler deiner Wahl (Dynamics2, Auphonic) auf -16 oder meinetwegen -14 LUFS bringen lässt, dazu noch ein gut eingestellter EQ - dann würde das IMHO reichen.
Die Frage ist ja: was ist die Alternative. Ich habe mal spaßenshalber einen herzhaften Kompressor auf deine Stimme gelegt, ich finde: das klingt nicht gut. Ich finde schon Auphonic für Hörbucher einen Tuck zu aggresiv, leise, dramatisch gesprochene Passagen gehen da schon unter und werden unnatürlich laut gezogen. Der Dynamics2 ist da durch die Einstellbarkeit etwas flexibler - ich erwarte bei einem Hörbuch, dass ich auch noch einen Unterschied zwischen leise und laut gesprochen höre.
Ein Kompressor mit “Punch” macht das alles doch nur immer nur schlimmer. Ich hasse Radio-Setups, wo immer alles dröhnt und in die Ohren gedrückt wird. Bei einem Hörbuch willst du doch gerade Emotionen transportieren - und nicht alles zudröhnen. Dringlichkeit und Spannung entsteht durch den Vortrag, nicht durch Technik.
Und ich fand den Unterschied zum “Profi” Beispiel jetzt auch nicht so um Größenordnungen. Und wenn, dann eben in der Art der Betonung, nicht der Audio-Technik. Am ehesten lohnt da noch mit dem EQ zu experimentieren, etwas mehr “Schmelz” in die Stimme (mittlere Höhen) etwa bringt viel mehr als “Punch”.
4 „Gefällt mir“
In der Zwischenzeit habe ich heute morgen nocheinmal eine weitere Datei (Nr. 5) gepostet, mit dem MIC-Gain auf Reglerstellung 14 Uhr.
Und darauf basierend habe ich das UltraschallDynamics-Plugin auf besagtem Track aktiviert und nach einigem Herumspielen auf folgenden Einstellungen belassen:
- LUFS -13
- Noisflloor -40
- Noisegate -30
und als Datei Nr. 5a xxxxxxxxxxxx.flac auch hinterlegt.
Nun komme ich dem eigentlichen Ziel etwas näher, das ist so in ungefähr die Richtung, die ich unter
WUMME versucht habe zu beschreiben. Es hört sich jetzt deutlich fetter und nah am Ohr an.
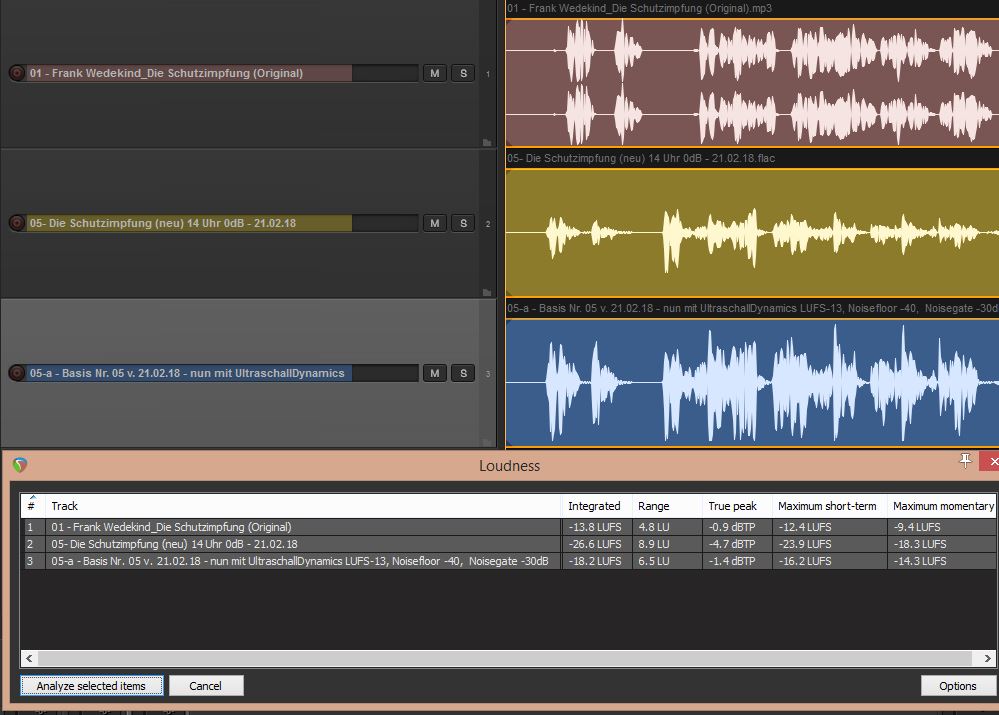
Ob die Werte allerdings optimal sind, vermag ich leider nicht zu sagen.
Vielleicht könnte sich ja nochmal wer Erbarmen, die Werte unter
Integrated | Range | True peak | Max short-term und | Max momentary zu erklären und in welche Range man hineinsollte?
Es wurde hier ja schon angesprochen: vielleicht ist zu viel Wumms gar nicht mal so wünschenswert. Wenn du eine sauber ausgesteuerte Aufnahme hast, die nicht rauscht (check) und die gut betont einsprichst (ausbaufähig, aber ich finde auch hier hast du schon ein ordentliches Niveau) und dann das durch einen Leveler deiner Wahl (Dynamics2, Auphonic) auf -16 oder meinetwegen -14 LUFS bringen lässt, dazu noch ein gut eingestellter EQ - dann würde das IMHO reichen
Voll meine Meinung. Bisher war es mir zu flach, aber wenn Du Dir nochmal die 5a anhörst, eigentlich wollte ich es so ungefähr … vielleicht eher noch weniger. Ich habe nur und ausschließlich die genannten Werte geändert. Abgesehen, dass ich als Sprecher an der einen und auch anderen Stelle gepatzt habe - aber darum sollte es hier ja gar nicht gehen - ist die Stimme nun näher am Ohr und ermöglicht eben auch, die kleinen Nuancen in der Stimme (im Beispiel nicht so viele vorhanden) mitzubekommen.
@hohony nimmt aber nun mal über ein Røde NT1-A auf (das er mir immer noch nicht angeboten hat ![]() ), und das ist nun mal ein ganz normales Mono-Mikrofon, wie es sich gehört.
), und das ist nun mal ein ganz normales Mono-Mikrofon, wie es sich gehört.
Wer Sprache über ein Stereomikrofon aufnimmt und das nicht schon im Mix auf Mono panned, gehört ohnehin geteert und gefedert.
Möge das Monitoring ihn wahnsinnig werden lassen.
Dem Kollegen, dem ich mein altes H4 verkauft habe, habe ich Kopfhörer aufgesetzt, Monitoring über das eingebaute X/Y eingeschaltet und mich während dessen um das H4 bewegt.
Der hat’s keine 30 Sekunden ausgehalten ohne dass ihm schwindlig wurde - aber immerhin wusste er danach die Einstellung „Mono-Mix“ im H4 zu würdigen (die ich beim H5 auf der L/R bitter vermisse und jedesmal nachbearbeiten muss).
Ich sitze gerade im Schnitt einer neuen Folge und stelle leider fest, dass wenn bei Ultraschall Dynamics ein Target von LUFS -16 einstelle, meine Spur schön auf genau -16 gezogen wird, während die andere Spur bei gleicher Einstellung real bei -12 landet. Wie kann ich das beheben?
Sinnvollster Weg wäre: den Dynamics2 auf der Master-Spur entfernen und stattdessen pro Spur einstellen. Dort kannst du dann wenn nötig das Target pro Spur korrigieren.
1 „Gefällt mir“
Danke!
Hab vergessen zu schreiben, dass ich den Dynamics nur pro Spur und nicht im Master. (Ist der im Master voreingestellt?!)