Seit Längerem beschäftige ich mich im Rahmen meiner Podcastproduktion mit der Lautheit von Podcasts. Die meisten Podcaster*innen werden mittlerweile vom Quasi-Lautheitsstandard der integrierten -16 LUFS für Stereo-Podcasts gehört haben. Bei diesen -16 LUFS handelt es sich um einen wichtigen Wert, der eine Aussage zur durchschnittlichen Lautheit eurer Podcast-Episode macht. Auch wichtig ist der max. true peak Wert, der – z.B. in dBTP – sagt, wie nahe die lauteste Stelle eures Podcasts von der maximalen Lautheit (0 dBTP) entfernt ist. („Maximal“ ist dabei ungenau: Die 0 dBTP können durch positive Werte überschritten werden, was dann aber in unangenehmem Clipping resultiert.)
Heute habe ich aus Neugier ein kleines Experiment gemacht: Ich habe eine aktuelle Produktion in zwei unterschiedliche Dateiformate (mp3 und m4a) enkodiert und danach erneut ausgemessen. Dabei wollte ich herausfinden, ob unterschiedliche Dateiformate die Lautheit beim Export unterschiedlich „verfälschen“. Dass eine Veränderung im Vergleich zu meiner verlustfreien Umgebung in meiner DAW resultieren wird, war mir dabei klar. Im Rahmen einer anschliessenden Diskussion der Resultate ist mir jedoch aufgefallen, dass dies vielen nicht bewusst ist. Man erwartet generell eine (minimale) Verschlechterung der hörbaren Audioqualität, nicht aber eine Veränderung der Lautheitswerte. Insofern profitiert hier vielleicht jemand von meinen Erkenntnissen.
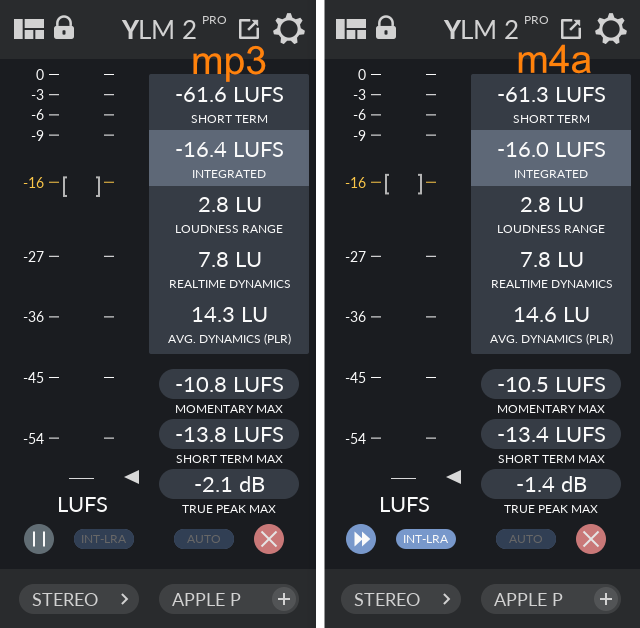
Die Messung meiner verlustfreien („pre-lossy“) Produktion (Stereo) innerhalb meiner DAW (Hindenburg Journalist Pro) hat vor dem Export einen integrierten LUFS-Wert von -16,0 ergeben; dies bei einem max. true peak von -2,4 dBTP. Alles bestens.
Das kleine Experiment
Erstellt wurden eine 80 kbps (Stereo) m4a- sowie eine 112 kbps (Joint-Stereo) mp3-Datei. Die unterschiedlichen Bitraten – wenn auch von der Audioqualität her einigermassen vergleichbar – wären allenfalls Anstoss weiterer Experimente, werden aber vorerst ausgeklammert. Nach dem Export haben die Messungen beider Audiodateien die folgenden Messwerte ergeben:
Um einige Auffälligkeiten herauszuheben:
Die gemessenen Lautheitswerte unterscheiden sich von jenen vor dem Export.
Die gewählten Dateiformate führen zu unterschiedlichen Ergebnissen bzgl. Lautheit.
Die integrierte Lautheit der m4a-Datei blieb stabil. Bei der mp3-Datei fand eine Verschiebung der integrierten Lautheit um -0,4 LU statt.
Beide max. true peak Werte sind nach dem Export näher bei 0 dBTP. Die m4a-Datei ist stärker betroffen.
LUFS, LU, blabla… und jetzt?
Aus diesem kleinen Experiment nehme ich weitere Learnings mit, welche während der Produktion zu beachten sind:
Die Messung in meiner DAW wird nicht mit dem finalen Produkt übereinstimmen. Faustregel: Die Entfernung zur pre-lossy Messung wird grösser, je verlustbehafteter ich enkodiere.
Vor dem finalen Export will ich meine Ziellautheit von integrierten -16,0 LUFS (Stereo) genau treffen, um das Risiko zu minimieren, nach dem Export durch eine kaum kontrollierbare Veränderung aus der Spezifikation (+/- 1,0 dB) zu fallen.
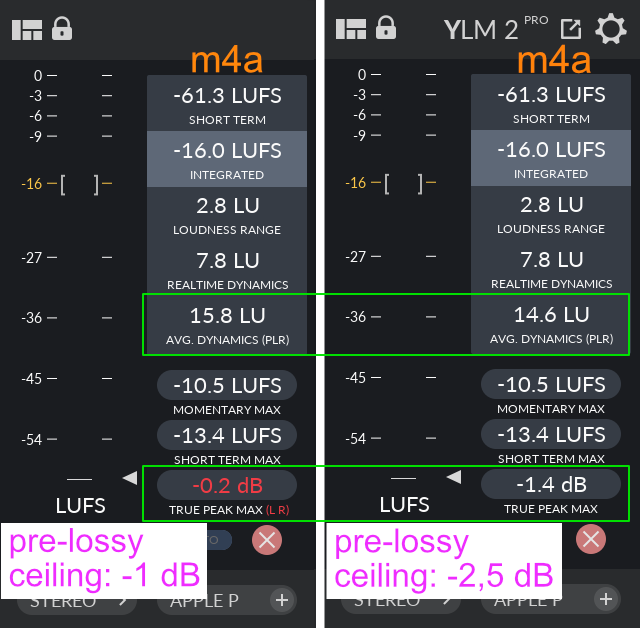
Nur weil die Spezifikation maximal -1,0 dBTP sagt, heisst das nicht, dass ich meinen Limiter simpel auf -1,0 dBTP einstellen kann. Das oft proklamierte pre-lossy max. true peak ceiling von -1,0 dBTP reicht nicht. Die Spezifikation bezieht sich auf das finale Produkt nach dem Export. Mein kleines Experiment hat eine Erhöhung von 1,0 dB ergeben (m4a-Datei). Wäre mein max. true peak vor dem Export schon bei diesen -1,0 dBTP gewesen, wäre ich nachher möglicherweise bereits bei heiklen 0 dBTP angekommen. Vor diesem Hintergrund erachte ich ein pre-lossy max. true peak ceiling von -2,0 dBTP bis -2,5 dBTP als empfehlenswerter. Dieser Punkt wird selbst für Auphonic-Nutzer*innen relevant sein, da Auphonic diesen Wert einstellen lässt.
Ja, das Loudness Target und vorallem die Peaks werden natürlich bei jeder belustbehafteten Kodierung verändert, das lässt sich leider nicht verhindern. Auch mit einem Limiter wird das Loudness Target immer verändert (Peaks werden abgeschnitten, das verändert wieder die Loudness und man muss verstärken, dann braucht man wieder den Limiter, usw.)
Aber man sollte sich da nicht unnötig beirren lassen:
Die Loudness Werte sind nicht so exakt zu sehen, es geht ja nur darum dass nicht unterschiedliche Produktionen komplett andere Loudness haben, ein paar LU auf oder ab fallen da nicht so ins Gewicht.
Viel wichtiger sind die Loudness Unterschiede innerhalb eines Podcasts - wir haben da ja einige Blog Posts in diese Richtung geschrieben, z.B.:
Zu einem Punkt muss ich aber was sagen:
Du hast bei deinen Ausführungen zum Peak natürlich recht, aber den MaxPeak auf -2dBTP absenken würde ich nur empfehlen, wenn du auch ein geringeres Loudness Target verwendest (<=-23LUFS)!
Ansonsten beschneidest du deine mögliche Dynamik extrem: bei einem Loudness Target von -16 LUFS mit -3 dbTP peaks, sind nur mehr 13dB von der Durschnittslautheit möglich (danach beschneidet der Limiter alles). Nun ist -16 LUFS generell schon viel zu hoch um eine komplexe Dynamik abzubilden (aber aus anderen Gründen notwendig), wenn du mit dem Peak Level auch noch runtergehst, beschneidest du permanent das Audio (für die gesamte Produktion), aus Angst vor ein paar Peak Overshoots (kommen vielleicht 1, 2 mal vor im gesamten Audio mit <1ms - und hören wird es wahrscheinlich niemand).
Deswegen sollte man achten, dass der Peak-to-loudness ratio mindestens >= 15dB ist (mehr hier: https://auphonic.com/blog/2019/06/12/the-new-loudness-target-war/#dynamic-range)
Fazit: Es ist alles ein Tradeoff und man sollte sich nicht auf einen Wert versteifen (es gibt noch viele andere die sehr wichtig sind) - das ist auch der Grund warum diese Einstellung bei uns versteckt ist
Diese Messwerte sind ja ganz schön, aber im Endeffekt zählt ob man es als Problem hören kann oder nicht …
Dass ein max. peak ceiling von -2,0 dBTP den maximal möglichen Dynamikumfang im Vergleich zum „traditionellen“ von -1,0 dBTP um 1,0 dB senkt, ist natürlich absolut richtig. Entsprechend habe ich das vor einiger Zeit ausprobiert um zu sehen, ob/wie stark das meine Produktion beschneiden würde.
Ich darf sagen, dass der gegen „oben“ um 1,0 dB reduzierte Dynamikumfang meine Produktion nur minimalst praktisch beschnitten hat. Dort wo eine seltene Beschneidung stattfand, war das gut. Wer im Bereich zwischen -1 und -2 eine dauerhafte Beschneidung feststellt, ist höchstwahrscheinlich viel zu laut. Hier sei zusätzlich angemerkt, dass ich „gewöhnliche“ Gesprächspodcasts produziere. Wer hingegen bewusst dynamische Produktionen baut, sei es mit Anteilen klassischer Musik, Flüstern und Schreien in Hörspielen oder Ähnlichem, der will sich dieses eine dB möglicherweise nicht nehmen lassen. Und nebenbei: Ja, die -3 dBTP aus deinem Beispiel erachte ich auch als zu viel des Guten.
Wenn wir nun bedenken, dass durch den Export eine Erhöhung des max. true peak um 1 dB stattfinden kann (in anderen Fällen sogar mehr), sehe ich aktuell leider keinen anderen Weg, als dies beim Headroom in der Produktion zu berücksichtigen, wenn man am Ende innerhalb der Quasi-Spezifikation bleiben will. Selbstverständlich kann man auch immer die Spezifikation in Frage stellen: Solange wir 0 dBTP nicht überschreiten, sollte das ja reichen. Ob man sich an diese Quasi-Spezifikation halten will, ist natürlich eine ganz andere Frage und nach wie vor freiwillig.
Mit Blick auf weitere Tests könnte man sich jedoch Fragen:
Die mp3-Datei zeigt einen kleineren Sprung des max. true peak. Wäre es in der Tat so, dass eine Enkodierung zu mp3 konstant und verlässlich einen lediglich kleinen max. true peak Sprung aufweisen wird, so wäre es natürlich sinnvoll, mit dem max. true peak ceiling in der Produktion wieder näher an die -1,0 dBTP zu rücken und sich damit ein bisschen Dynamik zurückzuholen. Ganz generell wäre es natürlich wunderbar, die durch Enkodierung verursachten Veränderungen der Lautheit voraussehen zu können. Auphonic hätte vielleicht genügend dieser Auswertungen, um (bald) Vorhersagen treffen zu können.
Noch schnell zum Schluss:
Die Beispiele auf dem Screenshot zeigen, dass dies (beinahe) möglich bleibt. Gut, in dem Fall war der PLR-Wert zufällig „nur“ 14,6 und nicht 15, fair enough. Wobei ich persönlich das Minimum eher bei 14 dB und nicht bei 15 dB ansetze, aber da wären wir erst recht im Territorium des Nicht-Standards für Podcasts.
Naja, diese Overshoots können aber auch leicht +6 dBTP bei dementsprechendem Material haben (gibt hier einige Papers dazu aus der EBU PLOUD Gruppe, die ich auf die Schnelle leider nicht mehr gefunden haben). D.h. die Overshoots zu verhindern wird bei einem Loudness Target -16 LUFS und lossy compression schwierig, außer du opferst die gesamte Dynamik (die eh schon klein ist) …
Der interessantere Punkt ist: Kannst du diese Overshoots wirklich hören (im Blindtest)?
Ja, das wäre natürlich möglich. Aber wie gesagt, uns ist die Dynamik wichtiger als mögliche, extrem kurzzeitige Overshoots. Das würde ich so auch jeder/m PodcasterIn empfehlen - aber es kann ja natürlich jede machen wie er/sie will …
Vielleicht war das rhetorisch etwas überspitzt und ich hab’s nicht gemerkt. Mein Vorschlag von einem pre-lossy max true peak ceiling von -2 dBTP reduziert die Dynamik – verglichen mit dem gängigen -1 dBTP ceiling – um 1 dB. Die „gesamte Dynamik“ opfere da niemand.
Das ist dann gleich der Übergang zu:
Vermutlich wird man hören, dass da was lauter war (vorausgesetzt eine genügende Zeitdauer). Hört man, ob es ein Overshoot war? Wie stark war der? Nein. Gleichermassen zweifle ich an, dass Hörer*innen benennen können, ob während der Produktion in der DAW das true peak max. ceiling auf -1 dBTP oder auf -2 dBTP eingestellt war. Bei Letzterem ist die Chane höher in-spec zu bleiben – falls man das will.
Natürlich absolut richtig.
Ich hätte ja nie gedacht, mal wegen 1 dB irgendwo derart viel Text zu schreiben.
Ja, ich will ja nur davor warnen, dass Sendegate PodcasterInnen auf Grund deiner Darstellung jetzt einen geringeren Peak Level einstellen wollen - das wird ja öfters mal „im Internet“ vorgeschlagen, diese Diskussion hab ich schon oft gehabt…
Weil dann sind wir schnell mal (wenn man wirklich ernsthaft Overshoots in lossy codecs verhindern will und Loudness Targets > -23 LUFS verwendet) wieder am Punkt, wo die ganzen Vorteile der Loudness Normalisierung (= größerer Dynamik Umfag) erst wieder weg sind - d.h. dann ist die Situation gleich wie im klassischen Loudness War …
Um den Effekt in der Praxis zu illustrieren und auch mal zu bebildern, wovon wir hier gerade schreiben, habe ich von der gleichen Produktion ausgehend nun einen Export (Enkodierung) mit dem „klassischen“ pre-lossy -1,0 dBTP ceiling erstellt und dem bisherigen aus dem Eingangsbeitrag gegenübergestellt:
Wie erwartet, haben sich zwei Werte verändert:
Bei einem pre-lossy max. true peak ceiling von -1,0 dBTP ist der resultierende (post-export) PLR-Wert höher (neu 15,8 LU).
Bei einem pre-lossy max. true peak ceiling von -1,0 dBTP ist der resultierende (post-export) max. true peak Wert ebenfalls höher (neu -0,2 dB).
Es ist eingetreten, was ich eingangs hervorheben wollte: Nun sind wir out of spec.
Ob es jemanden stört, dass wir nun mit dem traditionellen -1 dBTP ceiling aus der Spezifikation gefallen sind, oder ob das jemand hören wird, sind eigene Fragen. Beide kann man wohl mit Nein beantworten.
Kannst du auch die Waveforms der beiden Dateien posten? Dann sollte man schön sehen, wie die Datei mit -2.5 dBTP viel mehr zur „beschnittenen Audiowurscht“ wurde …
(Am besten die 2 Dateien auch hier reinstellen, dann kann jedeR das selbst im Audioeditor ansehen)
Ein .wav (oder überhaupt eine Datei) kann ich dir per 22. Dezember 2020 veröffentlichen.
Um noch nicht zu viel zu versprechen: Mir kam vorhin eine Idee und da bahnt sich vielleicht ein Plottwist an, an den noch niemand gedacht hat. Ich warte aktuell noch ein paar Rückmeldungen ab.
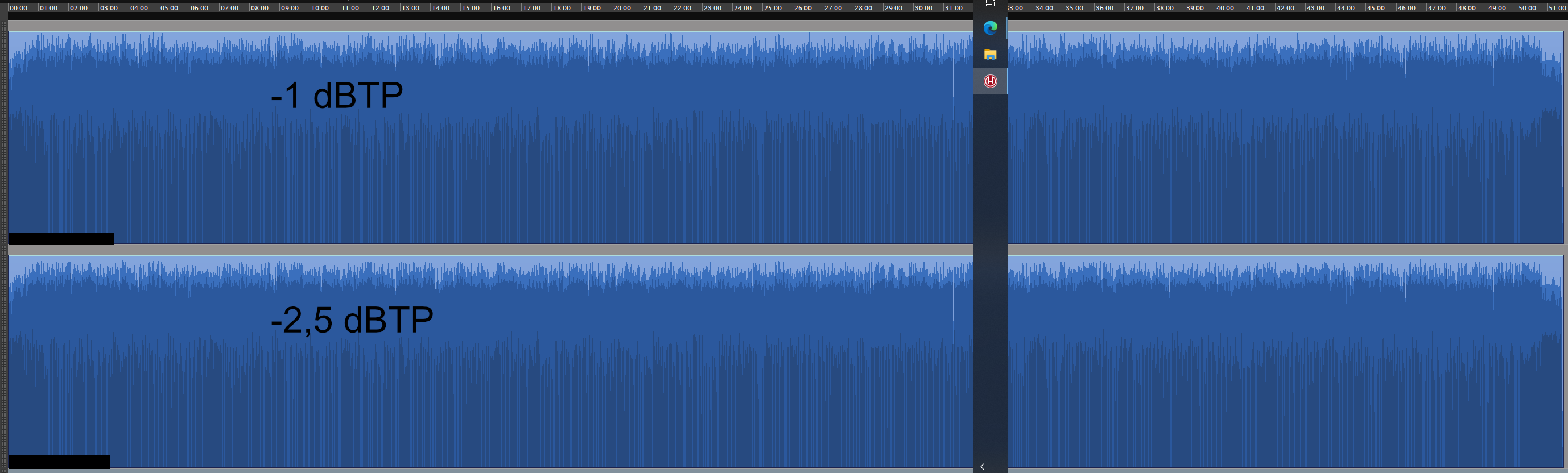
Da die Ansicht der ganzen Spur keinen grossen Unterschied zeigt, hier noch eine Detailansicht:
Hier sieht man, dass die Peaks – wie erwartet – teilweise nicht gleich hoch ragen.
Wenn du die Datei nicht posten kannst, bitte mach den Screenshot in audacity mit Default Einstellungen. In Hindenburg werden dir hier so weit ich weiß nicht die peaks angezeigt…
Hindenburg zeigt dir die klassischen Peaks sowie eine Aufteilung nach Frequenzbereichen – daher die zusätzlichen Blautöne, die nicht gleich hoch ragen. Korrektur: In der mehrfarbigen Ansicht bildet die dunkelste Farbe den RMS-Wert ab.
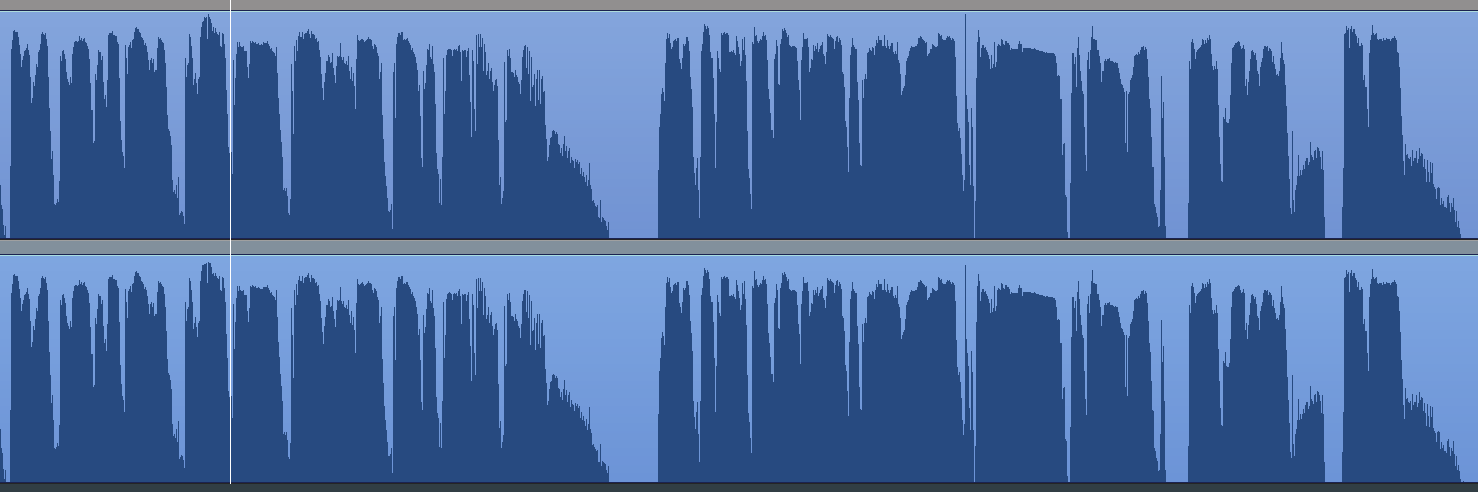
Die dedizierte Peaks-only Ansicht sieht so aus:
Anmerkung: Zuvor habe ich eine zufällige Detailansicht gewählt und diese jetzt auf die Schnelle natürlich nicht mehr gefunden. Ich meine aber, hier auch einen Ausschnitt gefunden zu haben, wo man die Unterschiede ebenfalls stellenweise erkennen kann.
Tut mir leid dass ich hier nochmal nachhaken muss, aber diese ganzen neumodischen Audioprogramme wie Hindenburg oder Auphonic haben hier wohl eine zu fancy Anzeige (und auch noch ohne Beschriftung)
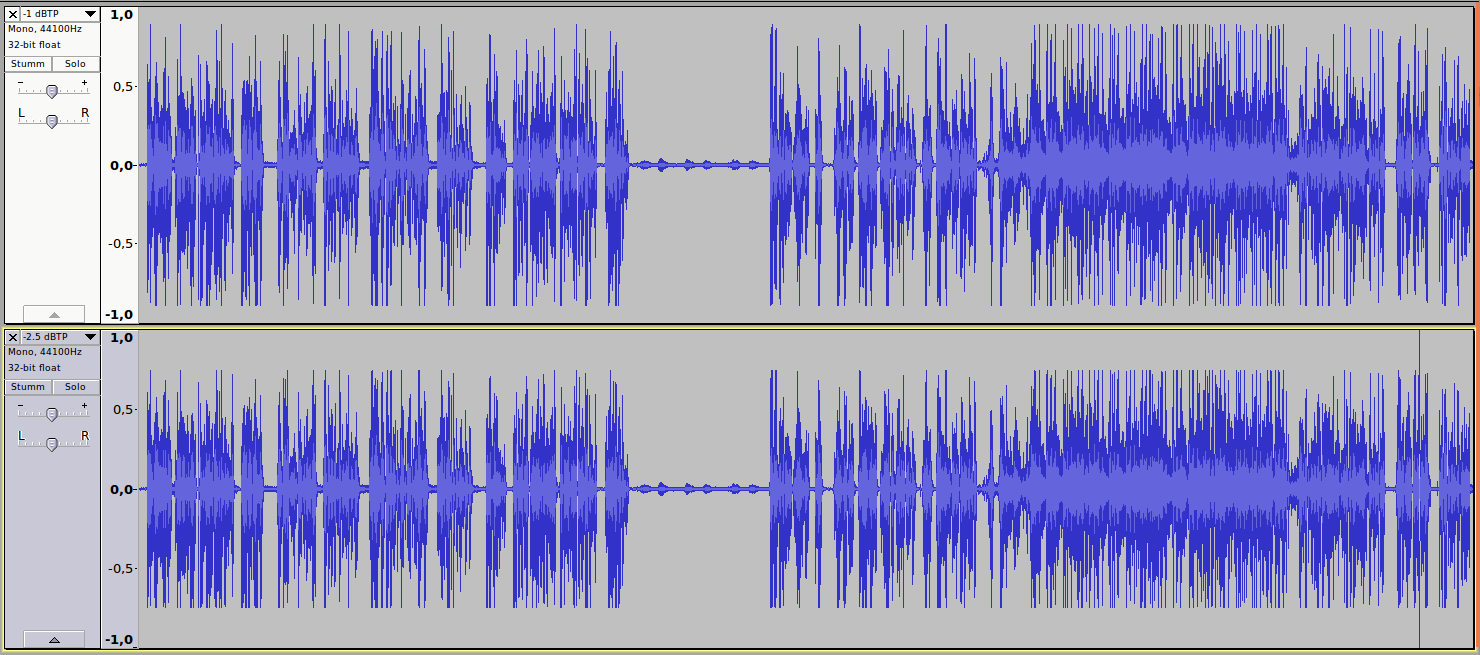
Nein, Spaß beiseite, für solche Analysen ist IMHO die wirklich klassische Ansicht (Peaks nach unten und oben) immer noch die Beste - hier sieht man was ich meine (-16 LUFS; oben -1 dBTP, unten -2.5 dBTP):
(das ist einfach die erste Datei von auphonic.com/audio_examples - die anderen werden ähnliche Ergebnisse liefern)
Was für mich der Punkt war:
Man sieht sehr schön, dass großflächig (fast überall) der Limiter viel härter arbeitet, dadurch natürlich mehr distortion entsteht, um ein paar potentielle Overshoots (die insgesamt wahrscheinlich nicht mal 1 ms ausmachen) zu verhinden.
Ist im Prinzip ein ähnlicher Prozess wie beim Loudness War …
Nachhaken ist immer willkommen. Je mehr Daten wir hier versammeln, umso besser.
In der Tat wird dein Beispiel viel deutlicher beschnitten. Ich habe den Grund zwischenzeitlich gefunden: Bei mir war vorab ein Kompressor am Werk, der die höchsten Peaks runtergeholt hat, sodass mein -2,5 dBTP ceiling nicht mehr derart viel zu tun hatte. Mein – zugegeben knapp zu tiefer – loudness range Wert von 2,8 LU hat das bereits angedeutet.
Zum Glück habe ich nichts versprochen. Da kommt wohl kein Plottwist. Ursprünglich habe ich mich gefragt, weshalb Apple ein -1 dBTP ceiling in der finalen Datei haben möchte. Was nützt das? Schliesslich soll nach der Produktion mein File gefälligst nicht mehr von Diensten modifiziert werden. Alles ≤ 0 dBTP müsste ja reichen. Das hat mich zur Spezifikation zurückgeführt und die Frage aufgeworfen, ob wir vielleicht die längste Zeit die Spezifikation falsch interpretiert haben könnten.
Klarheit brachte das nicht. Aus meiner Sicht könnte man diese Spezifikation betreffend dBTP ceiling auf zwei Arten verstehen. Deshalb habe ich das mit ein paar native speaker Produzenten angeschaut. Leider scheint wohl tatsächlich ein -1 dBTP ceiling betreffend finale Datei gemeint zu sein. Immerhin kamen Gründe zusammen, weshalb Apple das so haben wollen könnte: Offenbar kann insbesondere das Streaming (wenn auch nur temporär) wieder auf die Datei Einfluss nehmen und daher Headroom verlangen (besonders bei tiefen Datenraten/Buffer). Andere Gründe wären diverse „Enhancements“, welche gelegentlich von Podcatchern angeboten werden.