ich würde gerne bei einem Musikstück den Gesang weitesgehend raus editieren, so das nur die sonstigen Instrumente, sprich das übrige Lied übrig bleibt. Wie kann ich den Karaoke Effekt in Ultraschall umsetzen?
Mir ist bewusst, dass das Ergebnis je nach verwendeten Song unterschiedlich gut ausfällt. Über eine Step by Step Anleitung wäre ich trotzdem sehr dankbar
Hi, wir sind bekannter Maßen eine Podcast Community.
Was genau willst du mit Karaoke? Wenn dein Stück Gesang hat, dann kannst Du ihn ja einfach abschalten. Kannst du das nicht, dann ist es wohl nicht “Dein” Stück und damit für einen Podcast eh nicht nutzbar (Copyright).
Was für eine dämmliche Antwort. Ich kann echt nur den Kopf schütteln. Erstmal fragen bevor man hier Feststellungen oder halbgare Vermutungen los lässt. Ehrlich auf sowas kann ich echt gar nicht.
Zur eigentlichen Frage: ich würde da nicht viel Hoffnung sehen, dass so etwas in brauchbarer Qualität geht. Generell gäbe es da zumindest zwei Ansätze:
Mit einem EQ sehr gezielt die Frequenzen der Stimme runterregeln. Dafür muss man di aber erst mal messen, und menschliche Stimme hat dann doch auch schon einen recht großen Frequenzumfang. Sprich da wird dann auch jede Menge Musik mit rausgefiltert.
Man könnte versuchen den “Entrauschungs” Filter von Reaper zu benutzen. Der ist jedoch relativ kompliziert zu bedienen (daher von mir auch noch nie gezeigt) und vor allem würde er in deinem Fall nur dann was bringen, wenn du auch eine Passage mit NUR Stimme/Gesang hast, um damit einen Fingerprint anzulegen. Aber auch in dem Fall gilt die Einschränkung von 1. - die Musik wird sich danach grausig anhören.
tl;dr: mit vertretbarem Aufwand ist das vermutlich nicht möglich. Eventuell hat Adobe Audition da mehr zu bieten…
Ich kenne Ultraschall nicht und kann hier nur allgemeine Hinweise geben.
Die grundlegende Technik dieser Funktion basiert im wesentlichen auf dem Algorithmus, Mono- von Stereoanteilen zu trennen und die Monoanteile herauszurechnen.
Hintergrund: Gesang ist typischerweise Mono, Musik Stereo. - Hinweis: Bitte nicht in die Falle “Zweikanaligkeit muss Stereo sein” tappen! Stereo ist eine Laufzeitdifferenz, keine Kanalverteilung. -
Das funktioniert nur so lange zuverlässig, sofern der Gesang ausschließlich in Mono erfolgt und nicht im Mastering künstliche Stereoeffekte hinzugefügt wurden. In aller Regel funktioniert das mit einem background chorus (z.B. im Refrain) nicht mehr, weil dieser Effekt meist nicht mehr von Stereomusik zu trennen ist.
Letztlich hängt das Ergebnis vom Ausgangsmaterial ab und wie scharf oder unscharf das Programm den Effekt anwenden kann. Hier wird jedes Programm eigene Parameter zum Algorithmus mitbringen. Ob und wie man die beeinflussen kann, weiß ich nicht.
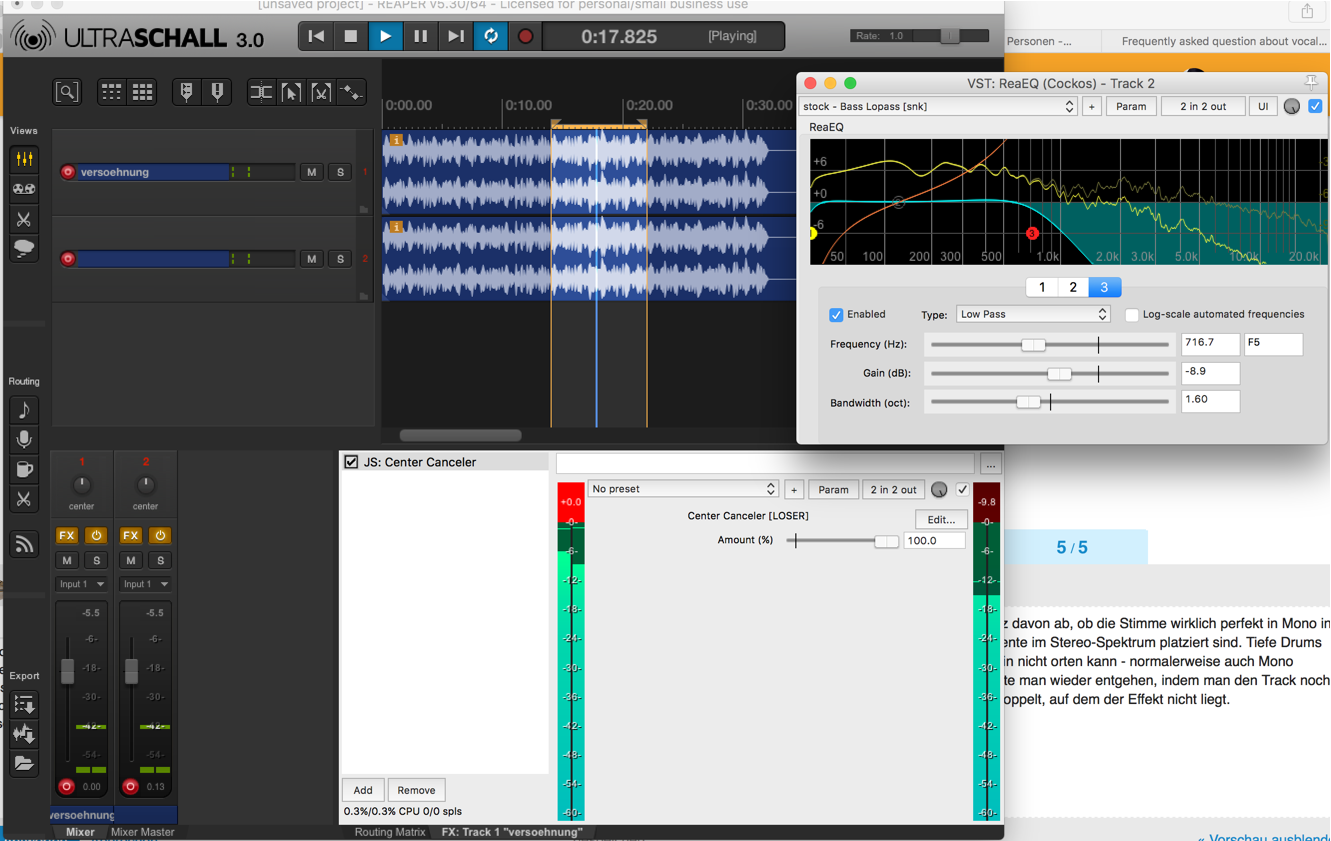
Ja, das kann man probieren: das Ergebnis hängt ganz davon ab, ob die Stimme wirklich perfekt in Mono in die Mitte gesetzt wurde, und wie die anderen Instrumente im Stereo-Spektrum platziert sind. Tiefe Drums etwa oder vor allem Bass werden - da man sie ohnehin nicht orten kann - normalerweise auch Mono gesetzt und verschwinden dann gleich mit. Dem könnte man wieder entgehen, indem man den Track noch einmal mit einem scharfen Lowpass-Filter versehen doppelt, auf dem der Effekt nicht liegt.
Das sähe dann so aus:
Auf dem Musik-Track legt man den Effekt “JS: Center Canceler” bei dem man noch mit einem Schieberegler die Stärke des Mitten-Rausrechnens bestimmen kann
Auf einem Duplizierten Track setzt man einen Low-Pass EQ Filter und stellt den so ein, dass möglichst wenig Stimme übrig bleibt, dafür aber etwas Bass und Drums hörbar sind.