Google hat bei mir eine leere Datei geliefert. 
1 „Gefällt mir“
Ich teste beide Varianten auch mal bei der nächsten Episode. Bin gespannt…
Bitte schicke uns Details zu deiner Production bei Problemen per mail - kann sein dass da noch was nicht ganz so rund läuft …
Die Audiotranskription ist um die Vorworte und ggf. Nachworte bereinigt, so ist nur der eigentlich vorgelesene Text aus Arthur Schopenhauers Über den Tod und sein Verhältnis zur Unzerstörbarkeit unseres Wesens an sich (iBook) eingetragen. Die einzelnen Dateien, mit den entsprechenden Hintergrundgeräuschen sind jeweils über den Tabellen zu finden. Um vergleichen zu können ist die Fragmentierung nach Sätzen am Originaltext vorgenommen, daher verschiebt sich die Stückelung der Dienste.
Leider fand ich nicht heraus, wie man hier Tabellen einfügen kann, so blieb mir nur das Bildschirmfort.
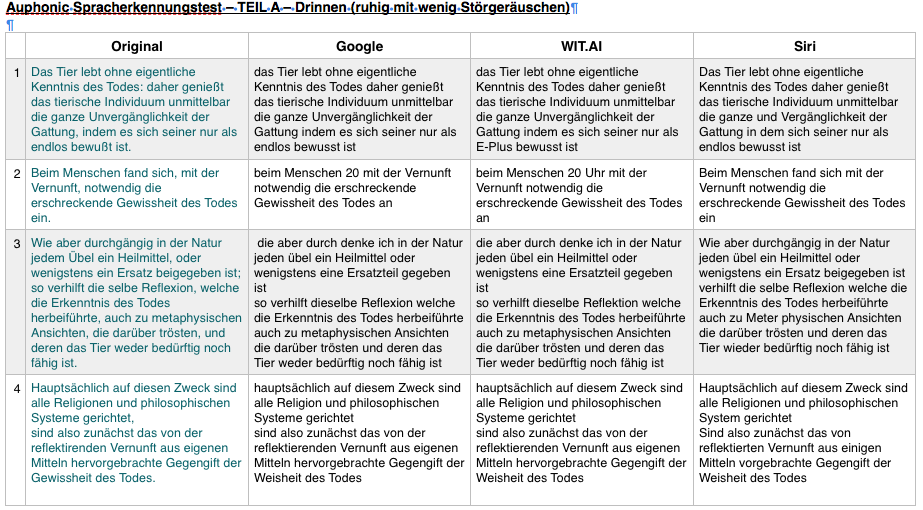
Auphonic Spracherkennungstest – TEIL A – Drinnen (ruhig mit wenig Störgeräuschen)
http://www.wilhelm-ahrendt.de/wp-content/uploads/podcast/wilhelm-ahrendt/labor/Sprachtest/Drinnen.m4a
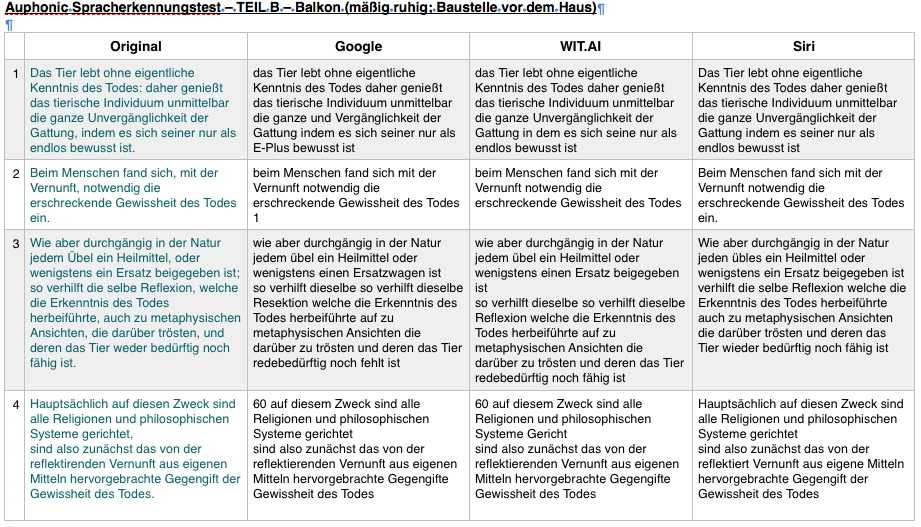
Auphonic Spracherkennungstest – TEIL B – Balkon (mäßig ruhig; Baustelle vor dem Haus)
http://www.wilhelm-ahrendt.de/wp-content/uploads/podcast/wilhelm-ahrendt/labor/Sprachtest/Balkon-maessig_ruhig.m4a
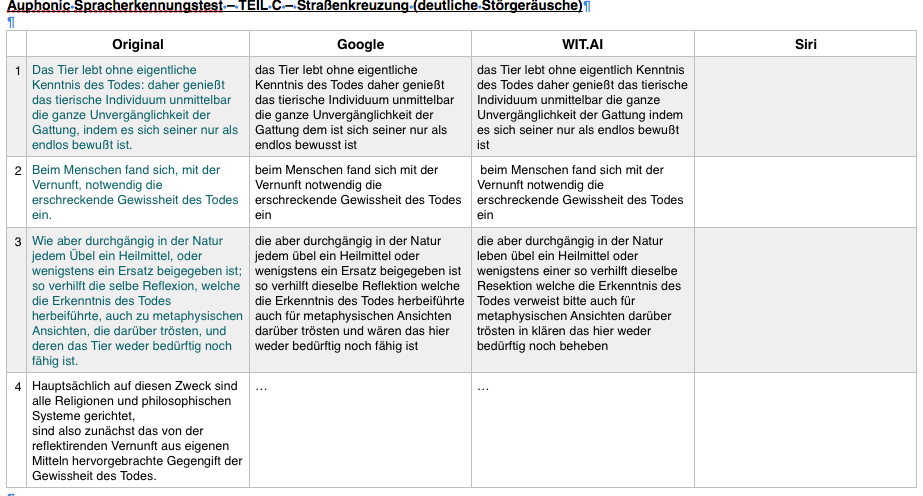
Auphonic Spracherkennungstest – TEIL C – Straßenkreuzung (deutliche Störgeräusche)
http://www.wilhelm-ahrendt.de/wp-content/uploads/podcast/wilhelm-ahrendt/labor/Sprachtest/Strassenkreuzung-laut.m4a
Erkenntnis:
Vermutlich ist für die Spracherkennung die Schwierigkeit nicht in der Verarbeitung von Sprache in lauter und geräuschvollen Umgebung, sondern ein durcheinander Sprechen – oder stark verhallten Aufnahmen. Dies wäre weiterer Tests würdig.
3 „Gefällt mir“
Danke, echt eine sehr schöne Gegenüberstellung!
Siri (oder die Android Spracherkennung, oder Nuance) ist auf deine Stimme angepasst, d.h. hier hast du automatisch viel bessere Ergebnisse. Dafür funktioniert es dann halt dementsprechend schlechter, wenn auch gemischte Sprecher sind.
Bei der Google Erkennung ist sicher noch viel Potenzial nach oben. Die Englische Variante ist z.B. schon viel besser. Die fangen erst an ihr System zu trainieren und sind ja immer noch erst in der Beta Phase - und suchen auch aktiv nach Partnern die sie mit Testdaten unterstützen:
in der Spracherkennung auf Android transkripieren sie wirklich die einzelnen Phrasen händisch um damit dann ihre Systeme zu trainieren.
Ihre Cloud Speech API ist ein anderes System, da wollen sie das auch machen und suchen dafür Daten (habe letzte Woche mit jemanden telefoniert) - in der Cloud Speech API werden die Daten jedoch nicht standardmäßig gespeichert (die von Auphonic natürlich auch nicht).
Jedenfalls wird das sicher noch um einiges genauer werden.
Apropos: warum fehlt Siri in Variante C?
Für mich ist die Spracherkennung super hilfreich. Ich mache sehr ausführlich Notizen, hiermit geht das sehr gut, selbst wenn die Systeme noch nicht optimal sind und das noch viel händisches nachjustieren bedeutet. WIT.AI ist besser als die Programme, die ich bisher getestet hatte (Dragon Dictation und Spracherkennung im Google Drive). Google werde ich auch noch testen, das wäre prinzipiell anfangs ja wohl unproblematisch. Meine Podcasts sind meist länger als eine Stunde, sodass langfristig Kosten bei Google auf mich zukämen (würden mich jetzt nicht arg stören), die Bezahlversion richtet sich jedoch an umsatzsteuerpflichtige Firmen/ Akteure. Hat damit schon jmd. Erfahrung, bzw. eine Einschätzung dazu? Vll. hab ich auch irgendwas übersehen?
1 „Gefällt mir“
Ich habe jetzt WIT.AT und die Google Speech API und ich muss sagen, dass in meinem Fall Google besser funktioniert.
Ich habe den Eindruck, dass die Ergebnisse mit Google besser sind, weil man hier “Spezialbegriffe” eintragen kann, die nicht deutsch sind.
Gibt es noch eine Chance an der Beta Teilzunehmen?
Hier versteckt sich die Anleitung und auch noch Invites, die bei mir gerade eben noch funktioniert haben ![]()
Schade ist es, dass ich für wit.ai (wenn ich das richtig sehe) einen GitHub oder Facebook-Account brauche.
Das habe ich nämlich beides nicht…
Ich probiere mal google, finde es aber auch schade, wenn man nachher nicht das ganze Projekt transkribieren kann, wenn man nicht nochmal Geld ausgeben will.
Aber das Konzept liebe ich. Es würde die Suche im eigenen, vor allem aber in fremden Podcasts super erleichtern.
Eine Lücke wird geschlossen  Danke dafür
Danke dafür 
1 „Gefällt mir“
Hier noch ein paar Invite Codes:
D48bwPvJSV kuWpBq3rCQ eah3CzOjyG lZwC13oQB7 zApe8Eu95Z e5rp85jA1G XVtnmvoCEp zlPdORG3gi Hapw1sKUcs 2jzR9TmGLn
1 „Gefällt mir“
Naja, ein github Account ist ja schnell mal erstellt ![]()
Danke! Sind jetzt dabei.
@auphonic Wie sieht euer Preismodell dafür nach der Betaphase aus?
@funkenstrahlen Unser Preismodell bleibt wie es ist. Spracherkennung ist ein “external service” bei uns, d.h. dadurch fallen bei Auphonic keine zusätzlichen Kosten an.
Wieviel das kostet hängt vom Service ab: wit.ai ist im Moment gratis, google cloud speech API hat ihr eigenes Preismodell!
1 „Gefällt mir“
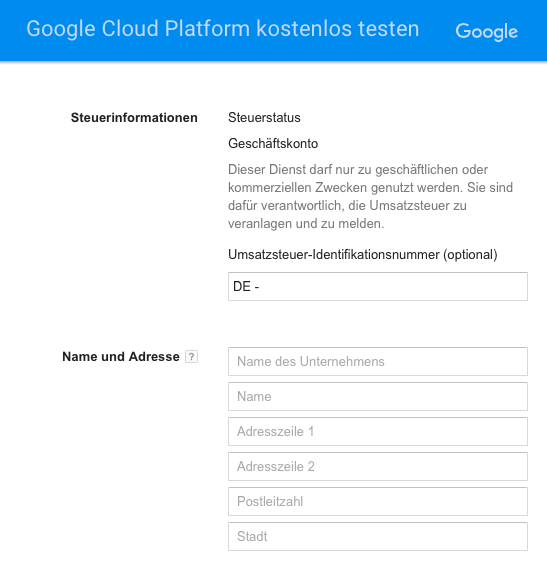
Ich hatte es oben in meinem Posting schon gefragt, weisst Du etwas dazu?
„Dieser Dienst darf nur zu geschäftlichen oder kommerziellen Zwecken genutzt werden. Sie sind dafür verantwortlich, die Umsatzsteuer zu veranlagen und zu melden.“
Kann man das ignorieren?
Was das rechtlich für dich persönlich heißt kann ich dir leider nicht beantworten - da müsstest du mal bitte bei Google nachfragen.
Aber ich schätze mal es geht denen hier um eine Absicherung, dass eben ein (kommerzieller) User für die Umsatzsteuer verantwortlich ist. Als Privatperson wird das wahrscheinlich keine Auswirkung haben (Achtung, ich habe keine Ahnung von deutschem Recht!) - zumindest kam das in der Kommunikation mit Google so rüber, dass das für alle verwendbar sein soll!
1 „Gefällt mir“
Siri hat nichts gemacht, kam nur der Kreis, vermute, dass es zu wuselig war.
Mir kommt gerade der Gedanke, dass solche Transkriptionen sich auch super als Google-Futter eignen, auch wenn sie nicht perfekt sind… Sprich sie könnten die SEO-Auffindbarkeit von Podcast-Folgen verbessern, wenn man den Text auf der Episodenseite einfügt.
Was ich cool fänd, wenn Ihr noch die beu Wit.ai ausgeworfene .SRT Datei noch zusätzlich in eine Textdatei konvertieren könntet, so dass ich das Transkript als .SRT mit Zeitmarken habe und als normale TXT ohne Zeitmarker, nur der reine transkribierte Text.
Das wär extrem hilfreich…
Edit: Wird eventuell auch Siri mal folgen?