Tool, macht aus .wav + Beschreibung schön getagte, ver-kapitelte mp3 und m4a Dateien.
Problemstellung
Nach dem Podcast-Schnitt will ich aus meinen Daten …
mp3 und m4a erzeugen
… mit Kapitelmarken in mp3
… und Kapitelmarken in m4a
… und mit id3 Tags und Bildern
… und das ganze offline
… und das ganze Open Source
… und auf Mac wie auch auf Linux funktionieren
… und das ganze via Kommandozeile
… und das Input-Format soll menschenlesbar sein
Weil es für jeden der Schritte jeweils Tools gibt, aber nichts, was alles auf einmal macht, habe ich ein kleines Werkzeug geschrieben. Das macht dann alle notwendigen Schritte nacheinander. Achtung: Das ganze ist noch in einer absolut ersten Entwicklungsphase, aber: Works for me.
Wie funktionierts?
Vorbereiten: Podcast als .wav, Kapitelmarken als .txt, Folgenbild als .jpg
Folgen-Definition ausfüllen.
Programm aufrufen: python3 tagcroft.py MEIN_PODCAST.wav MEINE_DEFINITION.yaml
Und schon purzeln schicke m4a und mp3 Dateien raus.
Man kann die Definition super wiederverwenden und schon im Vorfeld vorbereiten.
So eine Folgen-definition schaut dann etwas so aus:
---
track_number: 42
title: The name of the Podcast episode
date: 2018
subtitle: |
This is what the episode is all about,
information here.
description: |
This is a more eloquent description, usually
much longer than the subtitle.
keywords:
- Keywords
- Podcast
picture: artwork.jpg
chapters: chapters.txt
url: "http://github.com/derphilipp/tagcroft"
artist: The name of the Podcast
Wo bekomme ich das ganze?
Nochmal die Warnung: das ganze ist gerade erst ganz am Anfang und wirklich erst im entstehen.
Lieber Philipp,
vielen lieben Dank für die Bereitstellung Deines Tools. Ich würde es gerne einsetzen und habe bereits einige Hürden auf dem Weg dorthin meistern können. Ein Problem war, dass die Lizenz für libfdk_aac nicht mit der GPL kompatibel ist, weshalb eine kompilierte Version von FFmpeg, wie sie etwa von APT bereitgestellt wird, nicht eingesetzt werden kann. Das selber kompilieren von FFmpeg entsprechend dieser Anleitung hat mir da Abhilfe verschafft. Auch eine andere Fehlermeldung (fehlendes Modul ‘yaml’) konnte ich selbst beheben (pip3 install pyyaml).
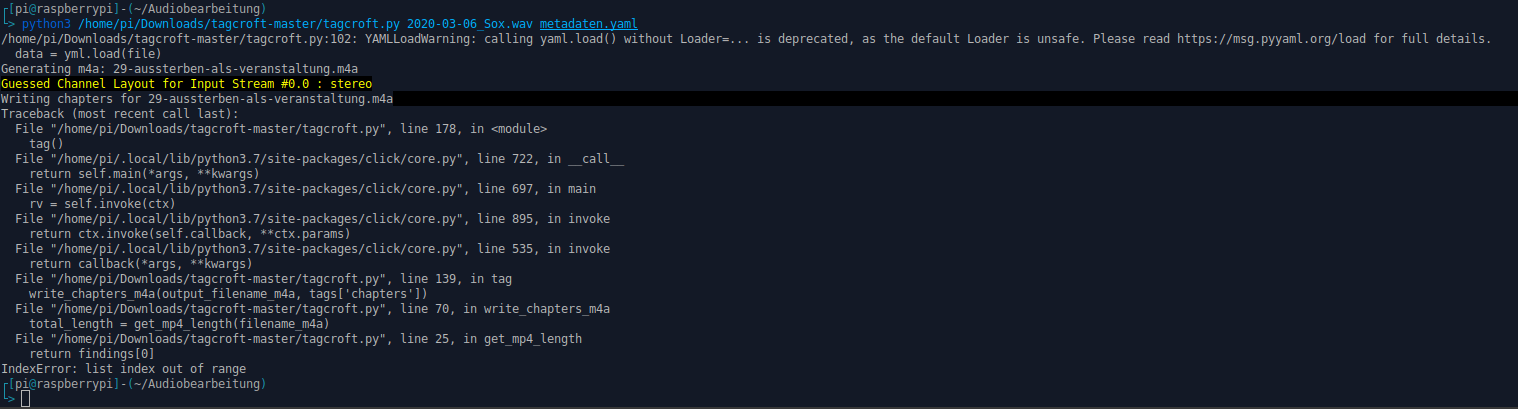
Das Python Skript legte anschliessend auch los und begann damit, erfolgreich eine m4a Datei anzulegen. Nachdem dieser Vorgang abgeschlossen war, brach es jedoch mit der Fehlermeldung “IndexError: list index out of range” ab.
Vielleicht hast Du oder jemand anderes eine Idee, woran das liegen könnte?
das Tool wurde nie zur “Marktreife” entwickelt, da Ultraschall in der kurz darauf erschienenen Version bereits all diese Funktionalitäten eingebaut hatte.
Nichtsdestotrotz vermute ich sehr stark, dass dein Kapitelmarken-File nicht in dem üblichen Format ist:
00:00:00.000 Intro
00:00:27.243 Was ist Halbgar?
00:01:06.151 Konzept Dostalgie
00:02:02.800 Intro Dostalgie
Der Ausdruck in der Zeile sucht nach ebendiesem Format
Vielen herzlichen Dank Philipp, ich hab mich sehr gefreut, bin aber selbst noch nicht dazu gekommen, mich meinem eigenen Workflow weiter zu widmen, in den ich Dein Tool einarbeiten möchte.
Es hängt allerdings auch noch an einer Stelle in Deinem Skript.
Ich habe den Verdacht, dass Du entweder grundsätzlich mit .mp4 Dateien gearbeitet hast, oder dass der Befehl “MP4Box” früher auch mit anderen Formaten als nur .mp4 umgehen konnte, was mittlerweile nicht mehr der Fall zu sein scheint: Ich kann mit MP4Box aus keiner .wav die Länge auslesen.
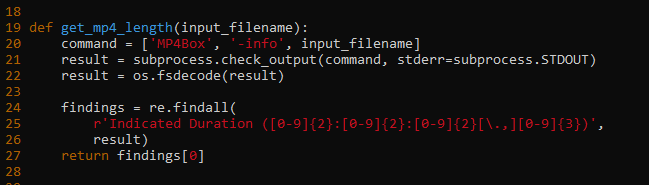
Spezifisch hängt das Script bei mir an dieser Stelle:
Momentan habe ich noch nicht die nötigen Python Kenntnisse, um das Skript kurzfristig so umzubauen, dass es die Länge der Audiodatei über ffmpeg herausbekommt und so der Befehl MP4Box verzichtbar wird. Ich denke darüber könnte das Script zum funktionieren gebracht werden. Befehle dafür kennt ffmpeg, nicht sicher bin ich mir allerdings, inwiefern die ausgeworfene Formatierung der Zeitangabe noch umzuändern wäre.
Falls Du Abhilfe weißt, vielen vielen vielen Dank im Voraus.
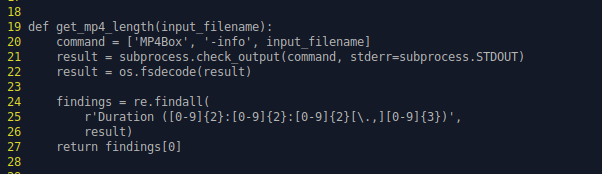
Ich konnte den Fehler bezüglich get_mp4_length finden und beheben. Ich habe mich bezüglich des Fehlers insofern getäuscht, als dass das Python Script korrekt die frisch exportierte .m4a Datei verwendet um daraus mit MP4Box die Dateilänge auszulesen und nicht die ursprüngliche .wav. Das ist soweit kein Problem und funktioniert grundsätzlich, außer dass das python Script nach einer “Indicated Duration” sucht, die im Ergebnis von “MP4Box -info dateiname.m4a” nicht vorkommt. Anscheinend wurde in irgendeinem update von MP4Box das “indicated” entfernt.
Wenn man dies im Script entsprechend ändert, funktioniert es bis dahin (Zeile 25, das “indicated” wurde entfernt).
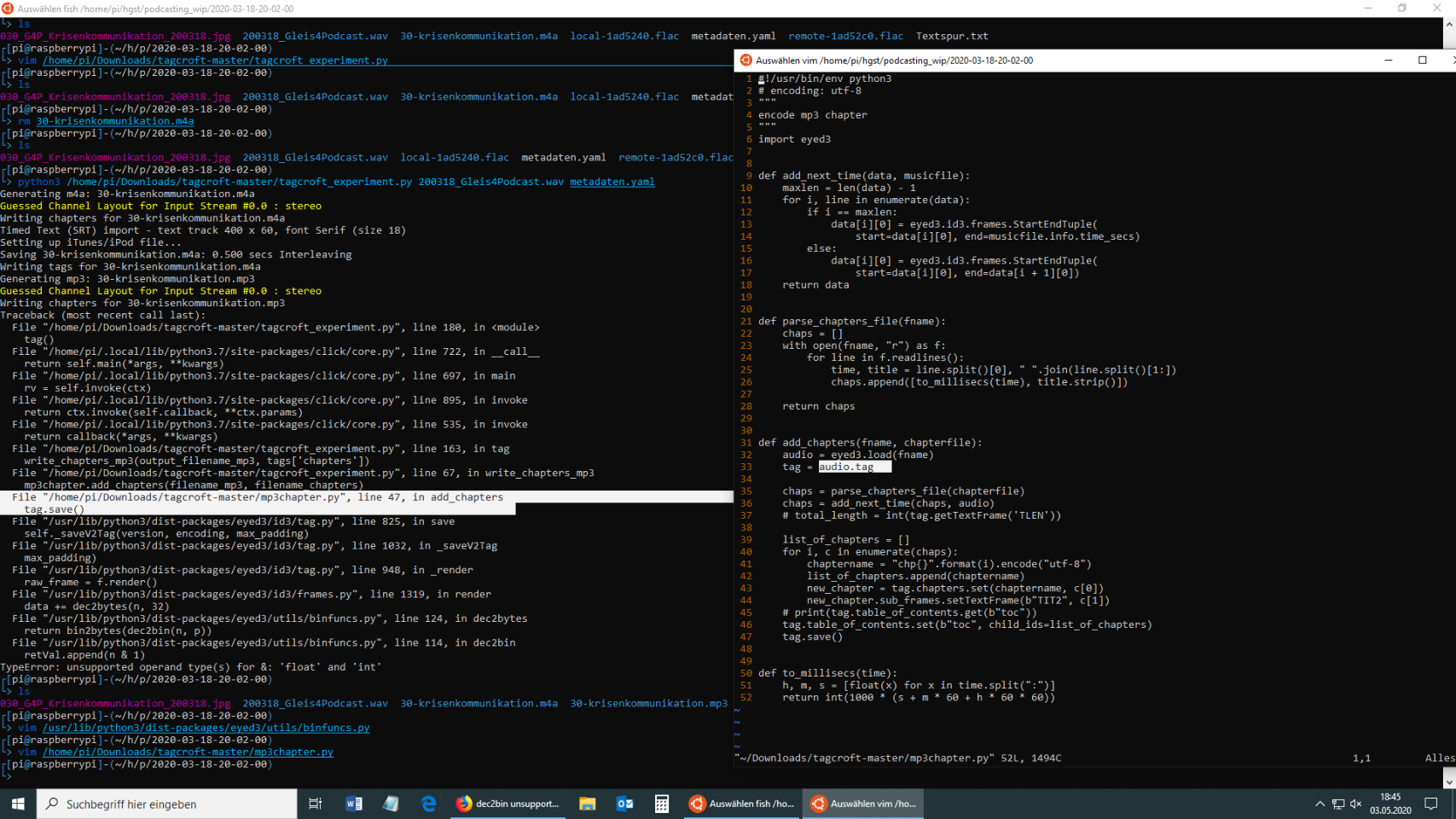
Im weiteren funktioniert erstmal alles, eine .m4a wird erfolgreich exportiert und mit Kapitelmarken und Metadaten versehen und eine .mp3 wird exportiert.
Hier gibt es allerdings dann als nächstes ein Problem damit, die Metadaten in die .mp3 zu schreiben. Dafür scheint eyed3 verwendet zu werden, wie es genau funktioniert, habe ich noch nicht verstanden. Jede Mithilfe ist herzlich Willkommen, wenn ich die Lösung finde melde ich mich erneut.
Nach kurzen drüberlesen würde ich sagen, die Datei wird nicht mit der ID3v2-Version 2.3.0 gespeichert. Und das ist erfahrungsgemäß die Version, die von den meisten Podcatchern verstanden wird. Und bei den TIT2-Frames fehlt das Encoding. Die Erfahrung sagt hier, dass UTF-16 bei allen Podcatchern angezeigt wird. D.h. alle die ich kenne und die Kapitelmarken anzeigen.