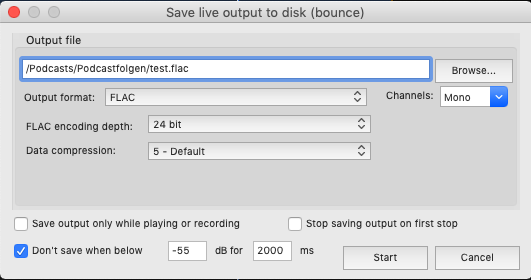
@friiyo Hi, ich bin mir nicht sicher was Du damit möchtest, bzw. was dein eigentliches Ziel ist?
Also Push-to-Talk ist eigentlich eine Radio-Situation. Weniger Podcast.
(Ich habe das jedoch auch mit in meinen MIDI-Controller UltraTouch V.6 gebastelt. Wenn alles klappt, stelle ich den nächstes Jahr mal vor.) Push-to-Talk bedeutet jedoch, dass jemand/Du einen Button gedrückt hält und auch nur so lange sprechen kannst, wie Du diesen gedrückt lässt.
Noise-Gate: (Noise=Rauschen, Zottern, Flattern; Gate=Tora, Tor, Tür, Verschließen, Zuschlagen, Entrücken). Dies hat eigentlich mit dem, was Du wünschst nichts direkt zu tun. Noise-Gate ist eben eine Rauschunterdrückung, die ab einer selbst festgelegten Lautheit (Unterschwelle) alle Signale darüber abriegelt. Dies gilt jedoch nicht während Du sprichst. Grundlegend ist es nichts weiter als eine Y-Korrektur mit Knee Funktion - also in jedem guten Kompressor vorhanden.
Hier könntest Du ansetzen. Ich habe aber verstanden, dass Du die Aufnahme stoppen möchtest, wenn Du nicht sprichst? Eigentlich sollte das mit ein wenig Lua-Code möglich sein (Ultraschall + Reaper). Jedoch verstehe ich nicht ganz warum Du solch einen Ansatz fahren möchtest? Er nimmt dir die komplette Kontrolle und braucht deutlich länger am Ende (Erfahrungsgemäß solltest Du Automationen erst im Nachgang anwenden -> weniger ist besser!).
Auch sehe ich weitere Punkte die hier einfallen können (aber nicht müssen):
1.) Wenn Du Stück-für-Stück aufzeichnest jedoch zu kurze “Happen” machst, geht der Flow und die Dynamik deiner Sätze kaputt und es hört sich sehr unrealistisch an. Des weiteren, geht deine normale Atmung in den Keller und das hört man sehr stark heraus. Mal zu leise dann Abrupt laut (Ansatz der Atmung).
2.) Auch Redest Du ohne Pausen, da Du zusätzlich keine “normale” Atmung mehr hast (Einatmen tust Du ja im Schnitt/Stopp/Pause).
3.) Ein weiteres Problem sehe ich auch, in der Psychoakustischen Wahrnehmung in der Art deines eigenen Sprachtaktes:
a.) Bei dem Du selber weist was Du einsprechen möchtest/eingesprochen hast, kannst Du nicht mehr ohne Kontext zu verstehen, nachhören. Wenn Du es dir am Ende anhörst, hat sich jedoch nix daran geändert - Du kennst den Satzbau. Du kennst den Kontext auch noch nach drei Wochen und Dein Gehirn kann sich nicht mehr auf die Dynamik konzentrieren. Damit nimmst Du dir die eigene Kontrolle über das was Du eigentlich aussagen oder letztlich Produzieren möchtest.
b.) Das bedeutet also: das Du die Geschwindigkeit von Reden-Hören-Verstehen (dahinter steckt ein Takt - klingt blöd; ist aber so), selbst nicht mehr wahrnehmen kannst (kann dein Gehirn auch nicht leisten) und damit keinen natürlichen Redefluss mehr hast. Für HörerInnen daher ohne Denkpausen/Unterbrechungen sprichst.
c.) Da der Kontext aber nicht alleine von den Wörter (Sprachsyntax) abhängig ist, sondern auch durch Atmung, Dynamik, Betonung, Dialekt, Kulturverständnis, Situation und Aussprache […] abhängig ist; stiftest Du damit mehr Verwirrung und klingst Obendrein wie ein Märchenerzähler.
d.) Für Leute die deine Sendung nicht kennen und zum ersten mal hören, springen bei so etwas, meist sehr viele HörerInnen ab. Da Du ein Wasserfall-Gespräch erzeugst, bei dem Du schneller sprichst, als die Leute Dir folgen (mitdenken) können. Das ist Kognitiv sehr anstrengend - auf kurz oder lang. Deshalb wird Sprache meist im Radio kurz gehalten und danach viel Gedüdel (wenn Sprache, dann Grinsebacken-Gespräche - bei dem das Grinsen zu hören ist).
Vielleicht können wir da was in Reaper basteln, da hat vielleicht @rstockm ne Idee?
Grüße M.C.