Wir haben soeben ein Ducking Feature in unserer Multitrack Version veröffentlicht:
Wenn man einen Track als Ducking markiert (siehe Screenshot), wird dessen Level automatisch runtergeregelt wenn in einer anderen Spur jemand spricht.
Das sollte hilfreich sein für Intros/Outros, Einspieler wo man auch mal drüberreden möchte etc.
Jede/r ist natürlich herzlich eingeladen das neue Feature zu testen - auch gerne mit experimentelleren Aufnahmen.
Bitte schickt einfach ein kurzes Feedback Mail und ihr bekommt die Credits für die Test Productions natürlich zurück!
Ja sehr schick! Auch wenn ich das eher in der DAW halten würde, da man dort direkt die Auswirkungen hören kann um feiner zu tunen wie man es haben möchte (Release-Zeiten etc.).
Kannst du die Parameter durchgeben die Ihr verwendet?
In einer meiner nächsten Ultraschall-Folgen werde ich das Ducking auch vorstellen.
Bei der Gelegenheit: was genau bewirkt die Einstellung Foreground/Background?
Bei Foreground/Background kannst du einstellen, ob deine Spur im Vordergrund oder im Hintergrund sein soll (und jetzt halt auch Ducking).
D.h. wenn du eine Musikspur auf “Background” stellst, wird sie im Hintergrund dazugemischt im Vergleich zu den Sprachspuren.
Ducking bedeutet eigentlich Vordergrund, aber wenn jemand spricht wird es in den Hintergrund gegeben (also eine Kombination aus beidem).
Auto entscheidet automatisiert für jedes Segment in der Musikspur (z.B. bei Intro, einem Einspieler wo man drüberredet, einem Musikstück, etc.), ob es im Hintergrund oder Vordergrund sein soll.
Hier ist ein Audiobeispiel dazu: https://auphonic.com/audio_examples#mt-example-3
Hier werden wir jetzt Ducking auch noch einbauen in den Klassifikator, d.h. es wird dann automatisch pro Segment entschieden ob Foreground, Background oder Ducking.
Danach wird es noch einen Blogpost geben, wo das nochmal genauer erklärt wird …
Zu den Ducking Parameter: da wird im Moment 0.5s vor und nach der Sprache rauf- bzw. runtergefaded!
Mir sind ein paar Dinge auch nicht ganz klar, obwohl die Dokumentation schon ein bisshen was andeutet (https://auphonic.com/audio_examples).
Auphonic passt ja die Levels der Spuren aneinander an, damit alles gleichmäßig laut ist - soweit alles klar. Aber, wenn ich z.B. einen Musik-Track habe der mit ca -18db vor sich hindudelt, was passiert genau bei:
Foreground"The music track is set to Foreground and its level won’t be reduced if speakers are active."
Bedeuete das, dass die Musik niemals angepasst wird - auch wenn kein Sprecher aktiv ist? Oder wird die Musik zu Anfang in ihrer Lautstärke an den Rest angepasst (genau wie die Stimmen aneinander angepasst werden)?
Background"Here the whole music track is set to Background. It won’t be amplified if speakers are inactive."
Auch hier für mich die Frage (wie bei Foreground), ob die Musik anfangs erstmal an die Speaker angepasst wird und danach um einen Prozentsatz vermindert? Und auch interessant: Wie leise wird die Musik genau? In welchem Verhältnis setzt Auphonic die Musik zur Sprache?
Mein Problem ist: Ich möchte ein paar Sounds im Hintergrund laufen lassen. Soll ich nun aber die Sounds in Reaper schön leise einstellen (so das sie perfekt zur Stimme passen) und diese Spur dann auf Foreground stellen? Das Problem dabei ist, dass ich ja noch nicht weiß, ob die Stimmen nach Auphonic lauter werden. Sollte dies passieren, sind meine Sounds vielleicht zu leise, wenn Auphonic bei der Foreground-Einstellung nichts an dieser Sound-Spur anpasst.
Ich kann die Sounds aber auch mit 100% Lautstärke rausrendern und dann Auphonic als Background mitgeben. Aber da weiß ich ja überhaupt nicht, WIE leise die am Ende sein werden.
Bei Foreground/Background verändern wir die relative Lautstärke innerhalb eines Musiksegmentes gar nicht. Jedes Musiksegment wird jedoch von der Lautstärke angepasst, so dass es zu den Lautstärken der Sprecher passt.
D.h. wenn du Foreground auswählst, werden Foreground-Stellen in deinem Musiksegment ähnlich laut wie die Stimmen sein.
Du kannst hier selbst ein Ducking in der DAW hinzufügen wenn du willst (diese relativen Lautstärkenunterschiede werden nicht geändert von uns), dann die Spur einfach auf Foreground setzen.
Bei Background wird das gesamte Musiksegment leiser als die Sprache gemacht, so dass die Sprache darüberspricht und noch verständlich ist (background track ist ca. 18dB leiser) - die relativen Lautstärken innerhalb des Musiksegments werden wiederum nicht geändert!
Bei Ducking ändern wir die Musiksegment: immer wenn jemand spricht, wird dieser Teil des Musiksegments abgesenkt!
Ah! Vielen vielen Dank für den tollen und schnellen Service! Ihr antwortet immer verdammt fix! Diese Details könnte man evtl. noch in der Dokumentation erwähnen - oder habe ich sie nur übersehen? Für den Profi ist sowas natürlich vielleicht selbsterklärend, aber für mich als Sound-Anfänger bringen diese Details etwas mehr Klarheit in die ganze Geschichte. Vielen Dank noch, und noch einen schönen Sonntag!
Oh, ich hatte diese Seite bisher übersehen und eher bei den Hörbeispielen gesucht. Ich finde es persönlich ein bisschen schwierig mich in der Dokumenation zurecht zu finden - zumal auf dieser Multitrack-Seite sowohl lizenz, best practices etc besprochen werden. Gibt es diese Infos auch strukturiert wie ein Wiki im Stile der API Dokumentation (https://auphonic.com/api-docs/multitrack.html)?
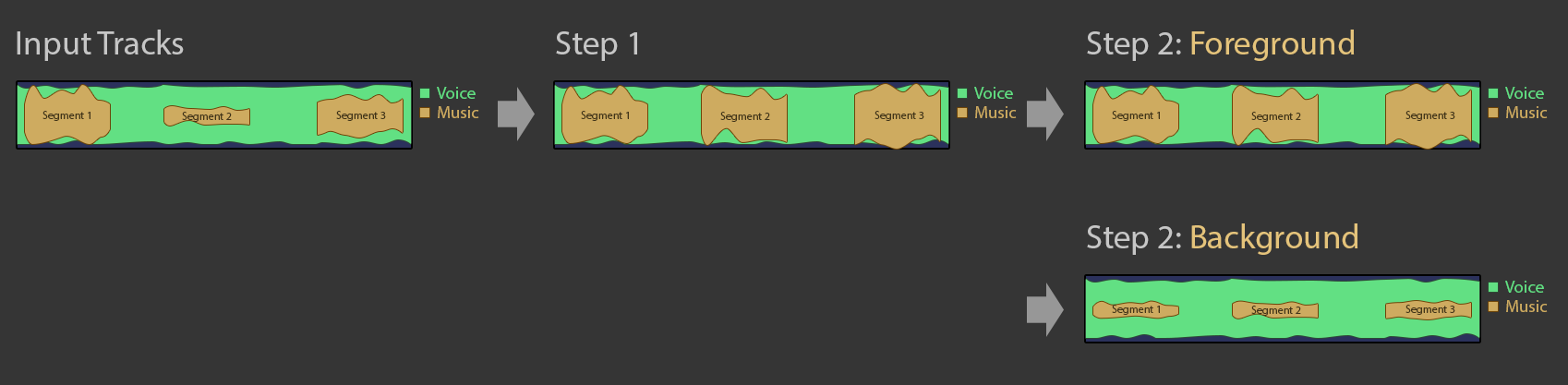
Ich hab es mal versuch in einer Grafik zusammenzufassen, Das sollte ungefähr hinkommen, oder?
Eine weitere Frage: Mein Podcast sieht ein bisschen so aus wie in dem Bild oben/links: Sprache-Tracks und dann gibt es ein relativ lautes Intro (Segment 1) und ab und zu unterlege ich die Sprache mit einer leiseren Musik (Segment 2) - In derselben Audio-Datei! Es handelt sich also um verschiedene Musik-Segmente. Wenn es so läuft, wie in meiner Grafik, würde meine ge-duckte Hintergrundmusik aber von Auphonic hoch-korregiert werden und bei einer “Foreground”-Einstellung dann viel zu laut zu hören sein.
Die Website sagt: “Use this option if music segments in this track should always have a similar loudness as speech tracks or if you add fade ins/outs or some ducking manually in your audio editor. All manual volume changes are preserved in Foreground mode.”
Aber irgendwie widersprechen sich da die Aussagen. Ich würde erwarten, dass bei Foreground alle Musiksegmente im Verhältnis zueinander “hochskaliert” werden, bis mind. eines von Ihnen ähnlich laut wie die Sprache ist. In meinem Falle wäre das automatisch so, weil das Intro ja schon relativ laut ist und dadurch würde dann auch nichts an meiner Hintergrundmusik verändert.
Oder richtet sich das nach dem Sprach-Track. Wenn der um 25% nach oben korregiert wurde, sich die Musik auch in diesem Verhältnis korregiert wird, um weiterhin so zu klingen wie in der DAW gewünscht?
Sehr schöne Grafik - ja, genau so funktioniert das!
Das mit der Doku stimmt auch, wir arbeiten gerade an einer (vollständigeren und besser strukturierten) Doku!
Ich bin mir nicht sicher ob ich deine Frage hier verstehe
Aber die einzelnen Musiksegmente in deiner Grafik oben werden alle extra behandelt, d.h. es macht für uns keinen Unterschied ob Segment 1 lauter/leiser als Segment 2 ist.
D.h. wenn du laute und leise Segmente hast kannst du folgendes machen:
Stelle die Spur in Auphonic auf Ducking, dann regeln wir immer die Lautstärke runter wenn ihr redet. Dann brauchst du in deinem Audio Editor die Spuren auch nicht leiser machen, das geht dann alles automatisch.
Mache eine Spur die du auf Foreground stellst und eine Spur die du auf Background stellst und teile die Segmente die im Fore- oder Background sein sollen dementsprechend auf die 2 Spuren auf.
Du könntest auch einfach „Auto“ verwenden, das sollte in 95% der Fälle funktionieren, kann aber leider nicht immer genau erahnen was du willst.
Ich habe neben den Voice-Tracks eine Spur die folgendes beinhaltet:
laute Musik (Intro)
leise Musik (Hintegrund)
medium laute SFX (Party-Tröte)
leise SFX (Chapter-Image-Ankündigung)
Meinen Arbeitsablauf würde ich gern so gestalten:
Ich ducke die Hintegrund-Musik und stelle die Lautstärke für Intro und SFX manuell ein, sodass sie perfekt passen
Ungern würde ich Musik und SFX in Vorder/Hintergrund-Spuren zusammenbringen, da ich die Lautstärken der Musik/SFX ganz gern via Track-Volume-Slider anpasse. Habe ich nur je eine Spur für Musik/SFX, kann ich diese verschiedenen Elemente (Musik, Party-Tröte, …) nicht mehr unabhängig von einander kontrollieren (es sei denn ich stelle es für jedes Audio-Segment im Track manuell ein)
Auch nicht so gern würde ich das Ducking von Auphonic machen lassen, da ich es nicht Preview-Hören kann und in Reaper bessere Kontrolle darüber habe. Außerdem würde Reaper die kurzen SFX (Chapter-Image-Ankündigung) vermutlich nicht ge-ducked bekommen, weil sie sehr sehr kurz sind und das Ducking ja meißt erst nach kurzer Zeit “soft” beginnt/aufhört.
Meine Befürchtung:
Beim nutzen der Foreground-Einstellung: Da Auphonic jedes Segment unabhängig voneinander an die Stimme anpasst, habe ich Angst, dass meine kurzen Chapter-Image-Sounds und die Hintergrund-Musik als einzelnes Segment erkannt werden und dann so laut eingestellt werde, dass sie so laut wie die Stimme selbst sind.
Beim nutzen der Background-Einstellung: Dies würde vermutlich für die Hintergrund-Musik und SFX funktionieren (wenn ich sie nicht ducke und mit 100% Volume übergebe), aber das Intro viel zu leise klingen lassen.
Hast du die beide Möglichkeiten oben probiert? Beide sollten ohne Probleme funktionieren.
Also:
Mach einfach alles in eine Spur und stelle sie auf Ducking, dann brauchst du in deiner DAW auch gar nichts anpassen. Alles geht voll automatisch.
oder:
Teile deine Musiksegmente in 2 Spuren auf (Fore und Background), in die eine gibts du die Foreground Elemente (Intro, SFX, etc.) und in die andere die Hintergrundmusik (diese Spur stellst du auf “Background”). Keine deiner Befürchtungen sollte ein Problem sein.
Am besten du probierst das mal, dann kannst du mir gerne den Link zur Production schicken wenn es Probleme gibt.
Ok, ich habe nun Folder-Tracks erstellt, damit ich nicht Musik und SFX zusammen in eine Spur packen muss. das hat gut funktioniert. So kann ich meine Tracks unabhängig in der Lautstärke regeln und am Ende einfach alles andere muten und die Tracks in eine Foreground und eine Background-Spur rendern.
Hallo @auphonic,
die Frage ist möglicherweise schon gestellt worden, aber ich habe die entsprechende Lösung leider nicht finden können.
Die Frage: wenn ich meinen Interview-Podcast mit #ultraschall geschnitten und zu einer Spur zusammengefasst habe, dann lade ich diese eine Gesamt-Spur stets noch bei Auphonic hoch.
Von mir im Schnitt zuvor runter gepegelte Background Geräusche/Musik etc. werden von Auphonic dann aber automatisiert wieder auf das gleiche Lautstärke-Niveau gehoben wie die Stimmen. Somit war die Arbeit zuvor eigentlich umsonst - also in Bezug auf unterschiedliche Lautstärke Niveaus.
Gibt es eine einfache Möglichkeit, dass zu umgehen? Also, die unterschiedlichen Lautstärken beizubehalten?
Dankeschön!
…solltest dann aber schauen, ob die Gesamtlautstärke auch passt, sprich zumindest irgendwo zwischen -18LUFS und -16LUFS landet. Der einfachste Weg wäre da, die Soundspuren mit Ducking so zu lassen wie sie sind, und auf die Sprachspuren den Ultraschall Dynamics 2 Effkt zu legen wie hier beschrieben:
Solange du die „Loudness Normalization“ bei uns an lässt, ist das kein Problem, diese regelt ja die Gesamtlautstärke!
Der „Adaptive Leveler“ regelt die relativen Lautstärken, welche eben nicht verändert werden sollen …