Hallo,
ich arbeite an einem Podcast in dem es um die Geschichte und Philosophie von GNU, Unix, Linux und Open Source geht. Für die Vorbereitung einer Folge möchte ich die gesammelten Informationen sortieren und miteinander korrelieren.
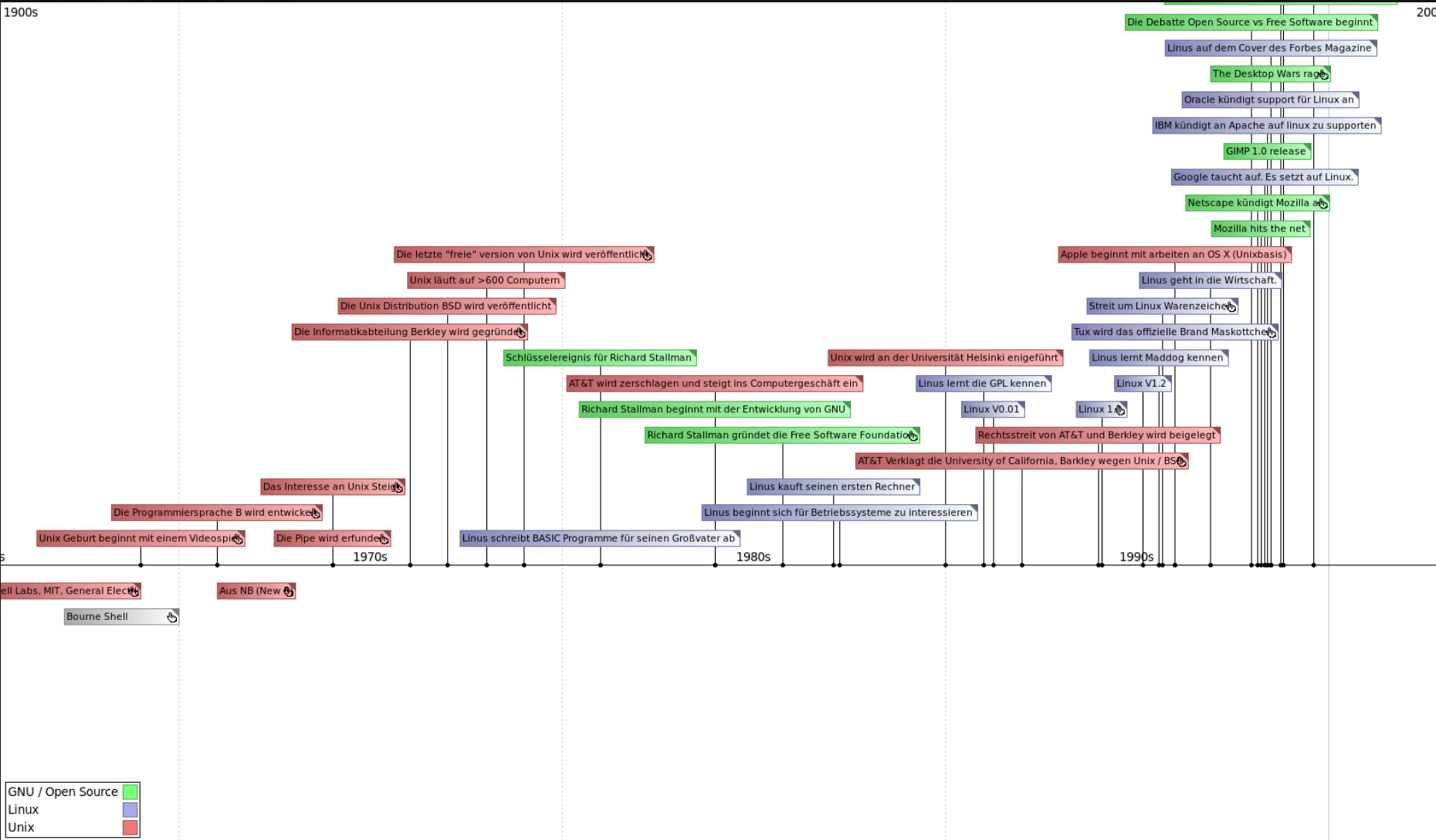
Am Ende möchte ich eine Grafik haben, die ich während der Sendung benutzen kann, um mich thematisch daran entlangzuhangeln.
Das sieht aktuell etwa so aus, damit bin ich aber noch nicht glücklich.
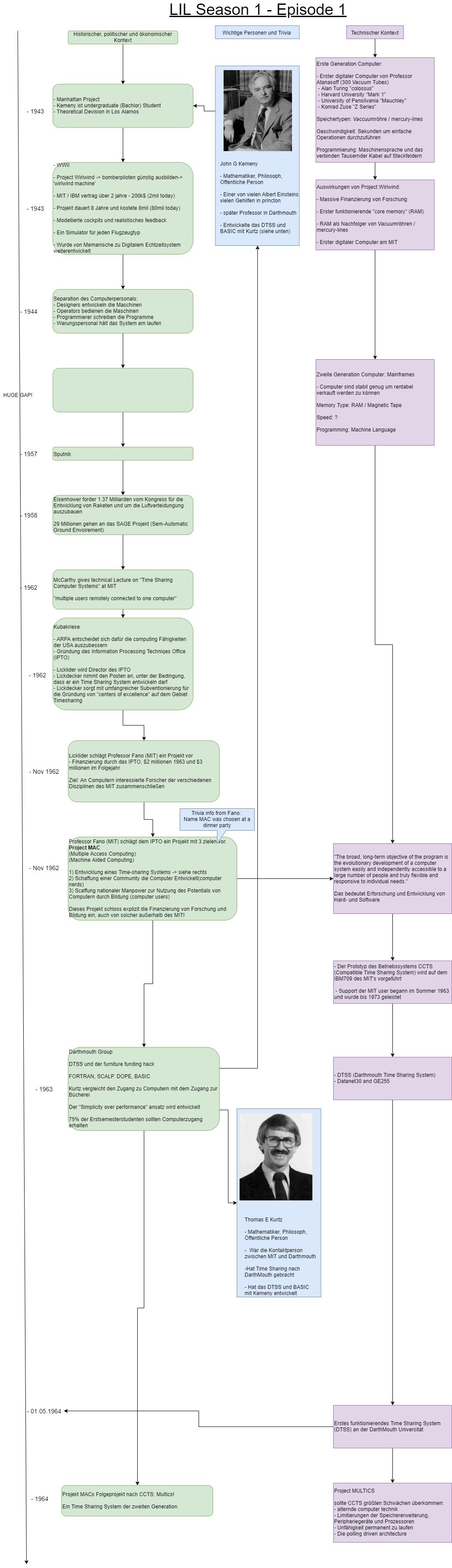
Um aus meinen Daten diese “Infografik” zu bauen, muss ich sie sowohl thematisch als auch zeitlich sortieren.
Das Hatte ich mit dem “TimeLine Project” versucht, das sah dann so aus.
Mit zunehmender Menge an Datenpunkten, Themen sowie den Verbindungen von Themen, Personen, Meinungen, Projekten und das ganze sortiert entlang der Zeitachse wurde das aber unübersichtlich.
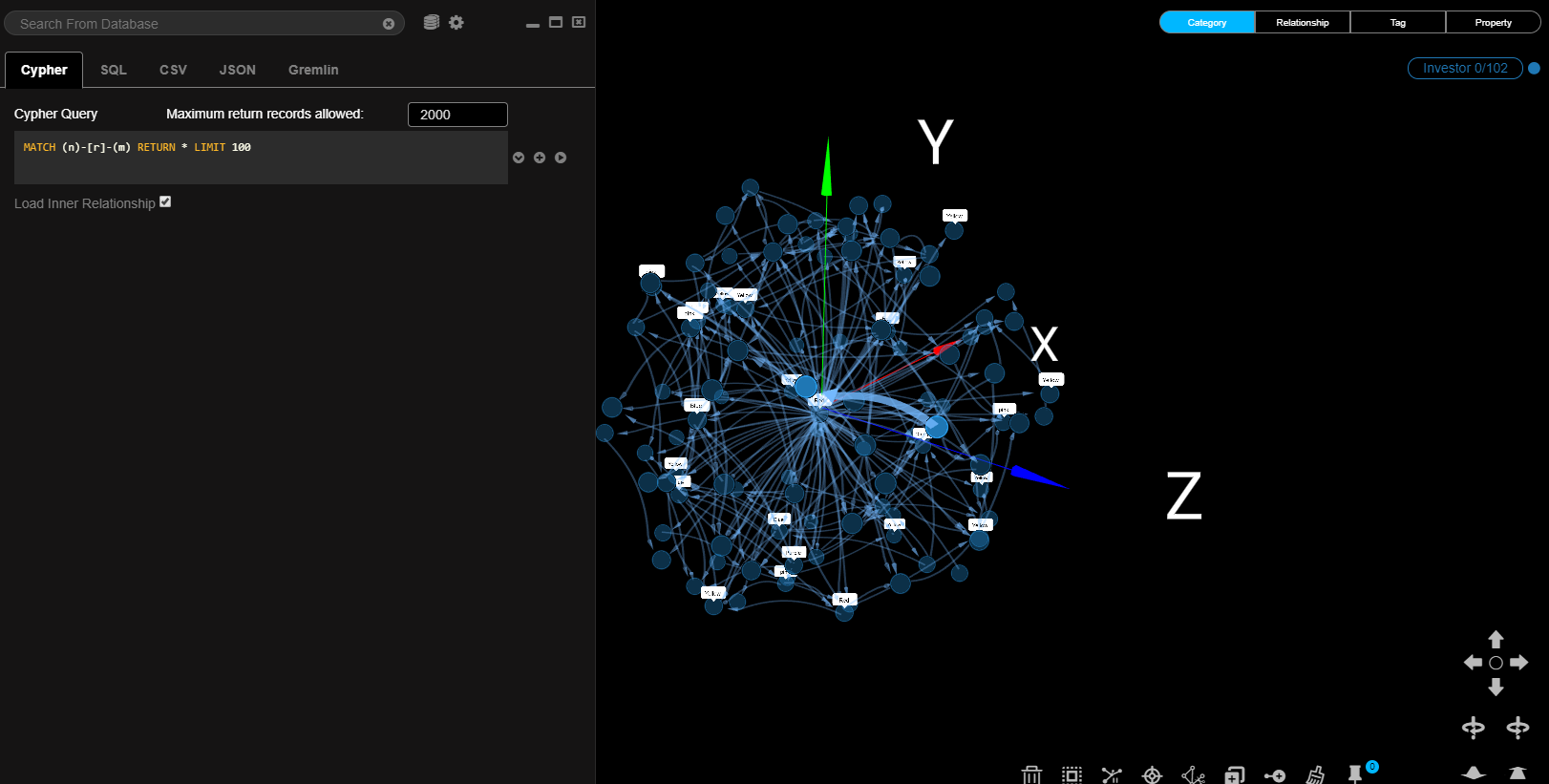
Also suchte ich nach einem Werkzeug um die Themen besser sortieren zu können.
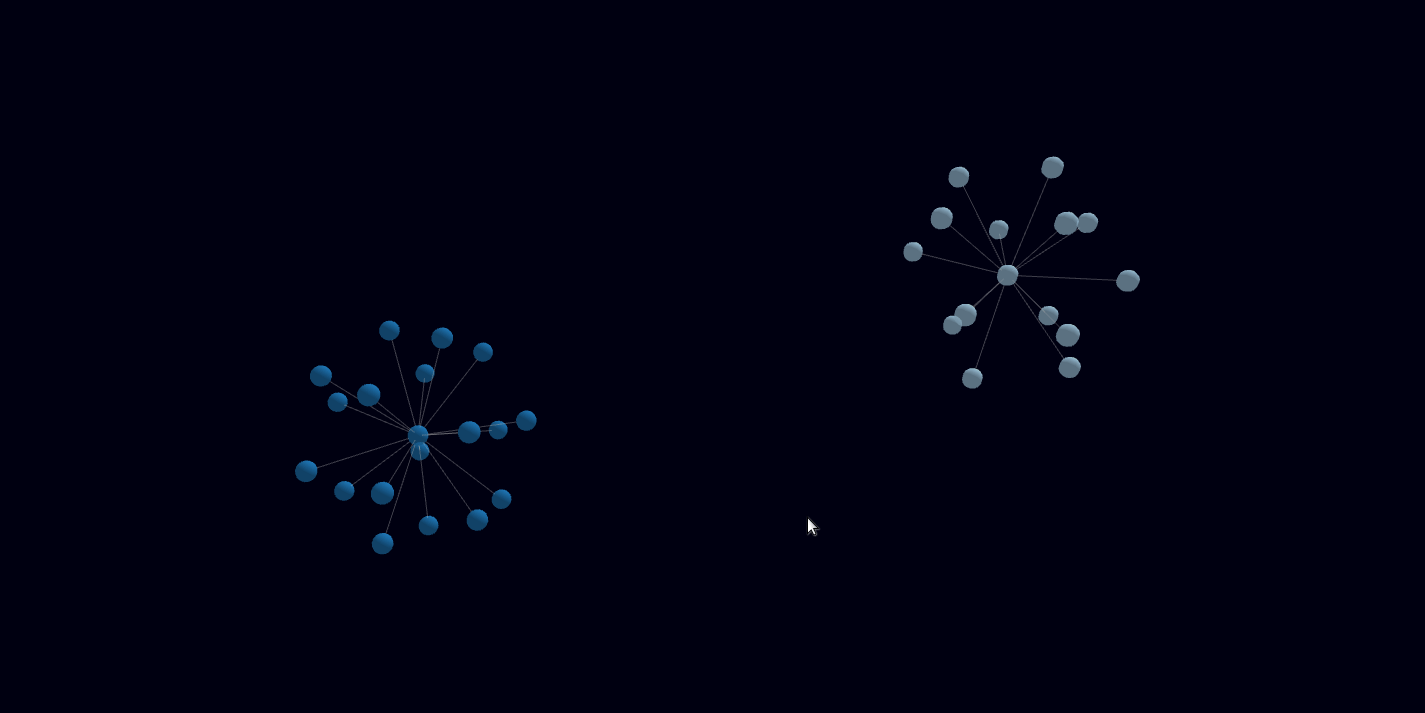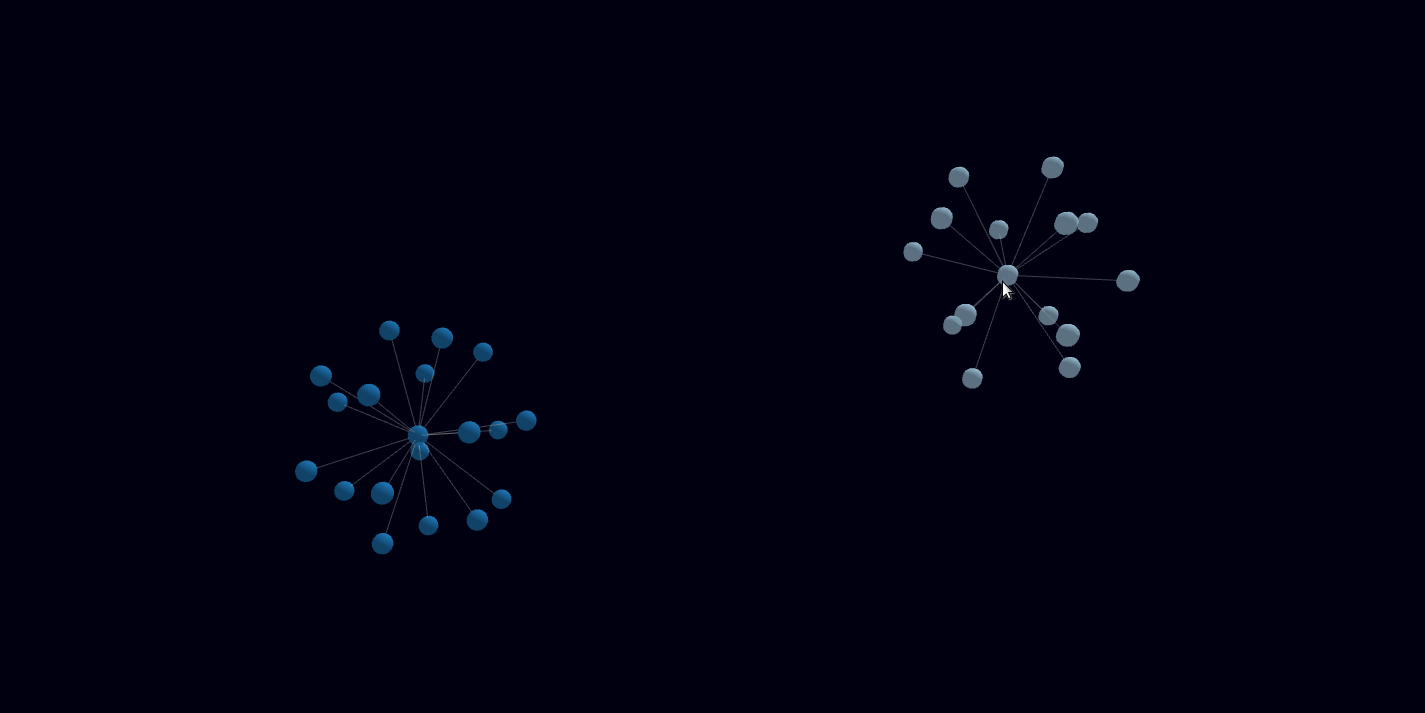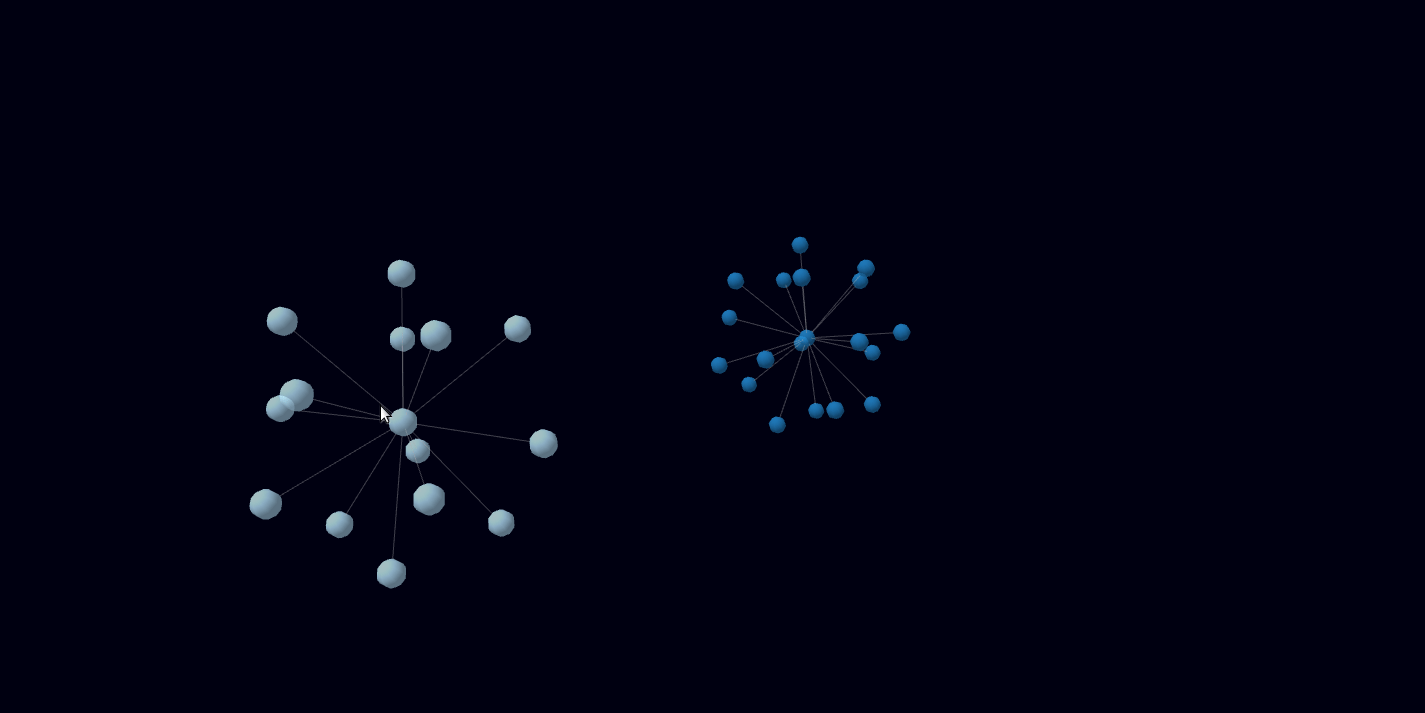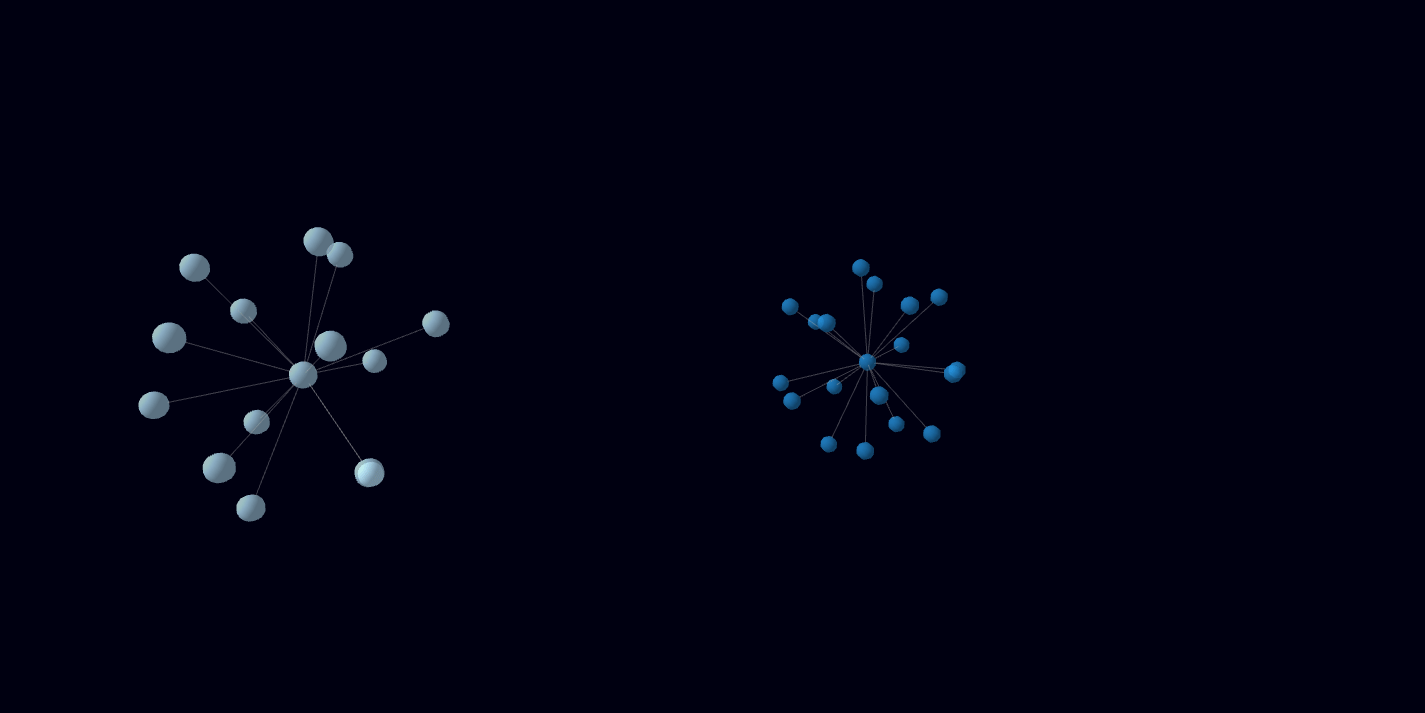
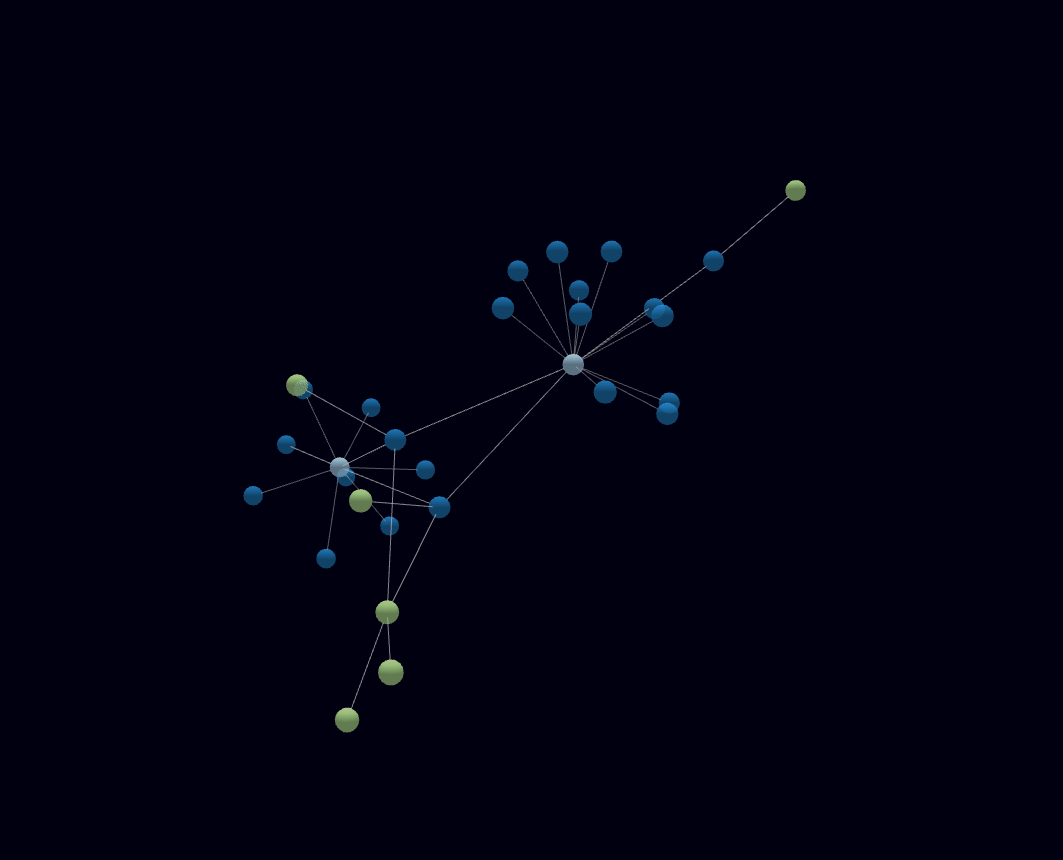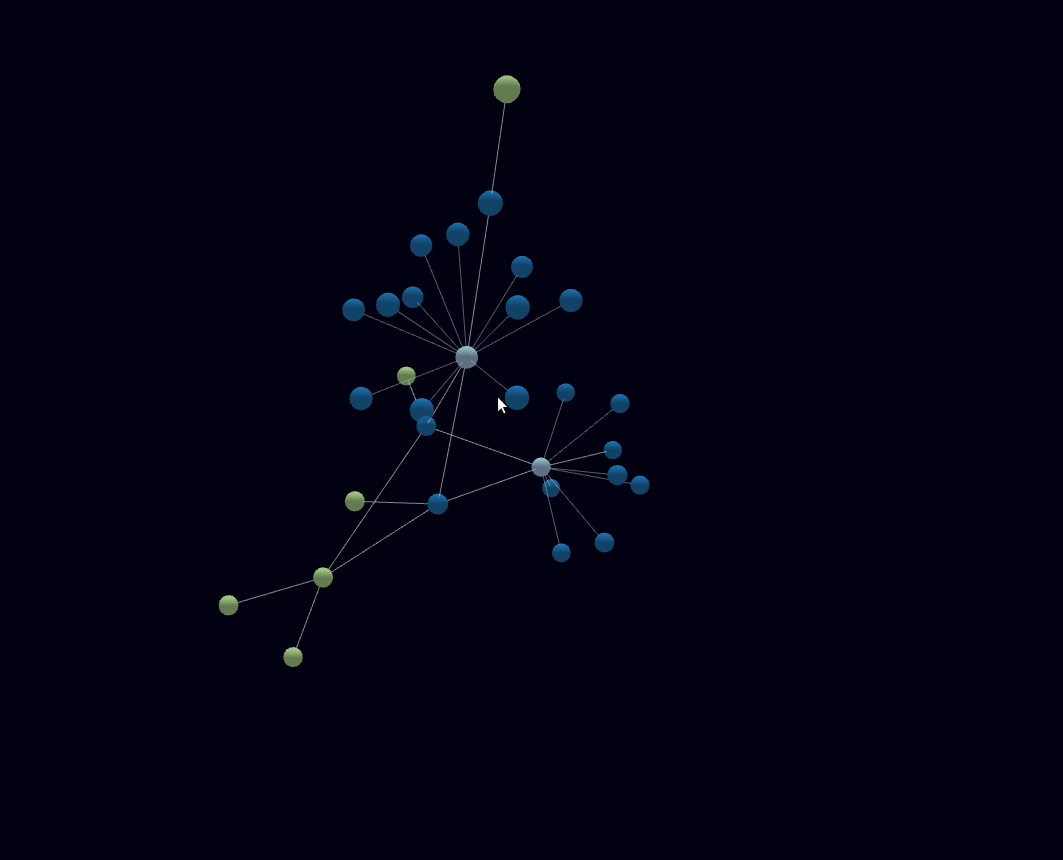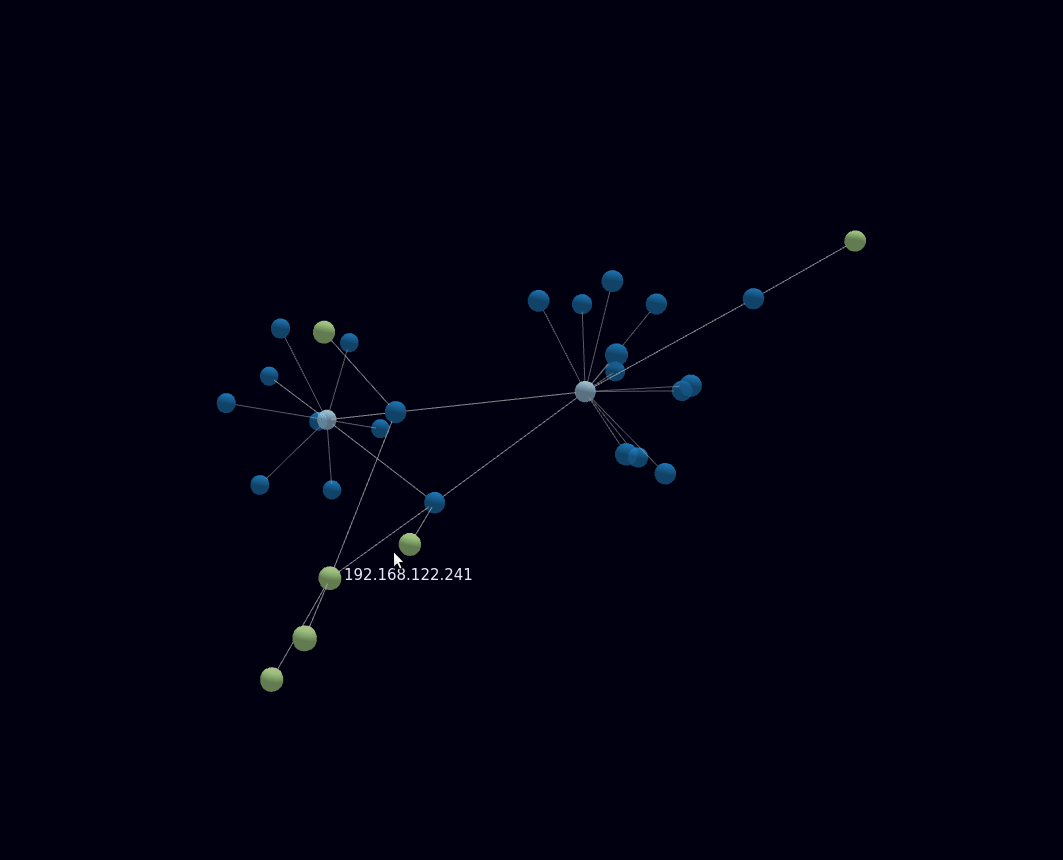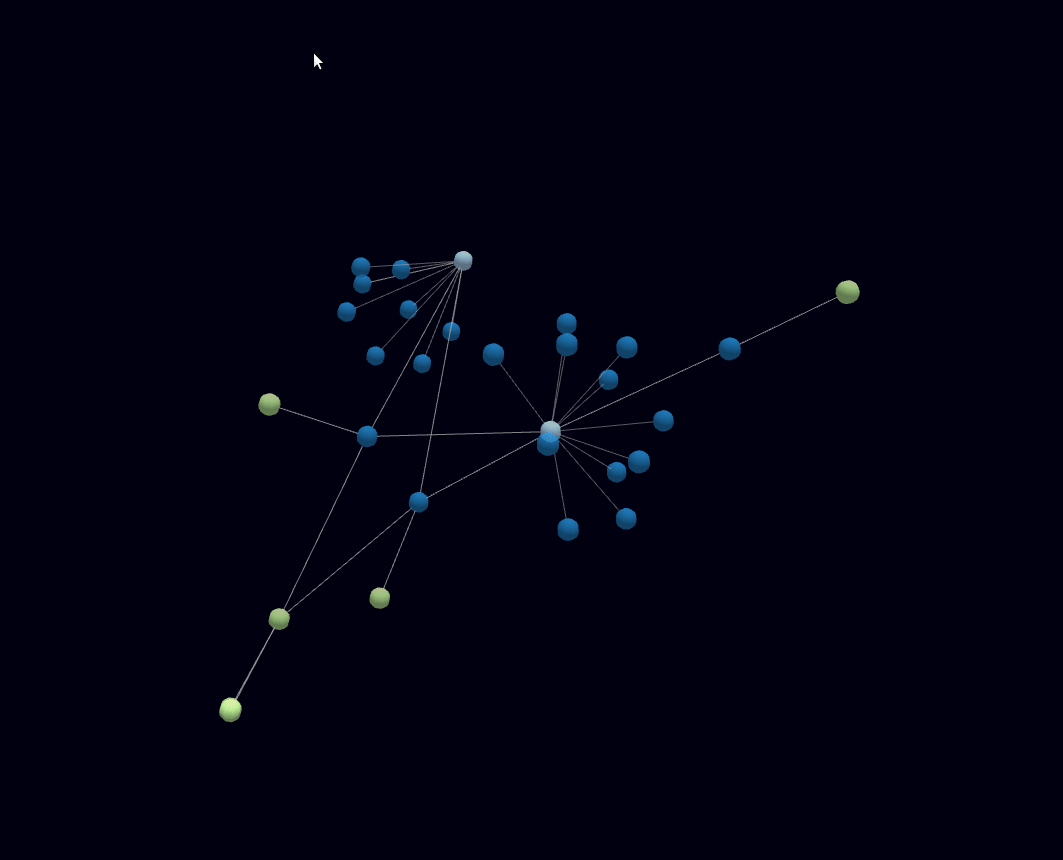
Dabei bin ich auf forcegraph3d gestoßen und hab einfach damit angefangen.
Ich nehmen gerne auch ein 2D Tool, wenn ihr ein gutes kennt.
Ich habe sowas halt noch nie gemacht.
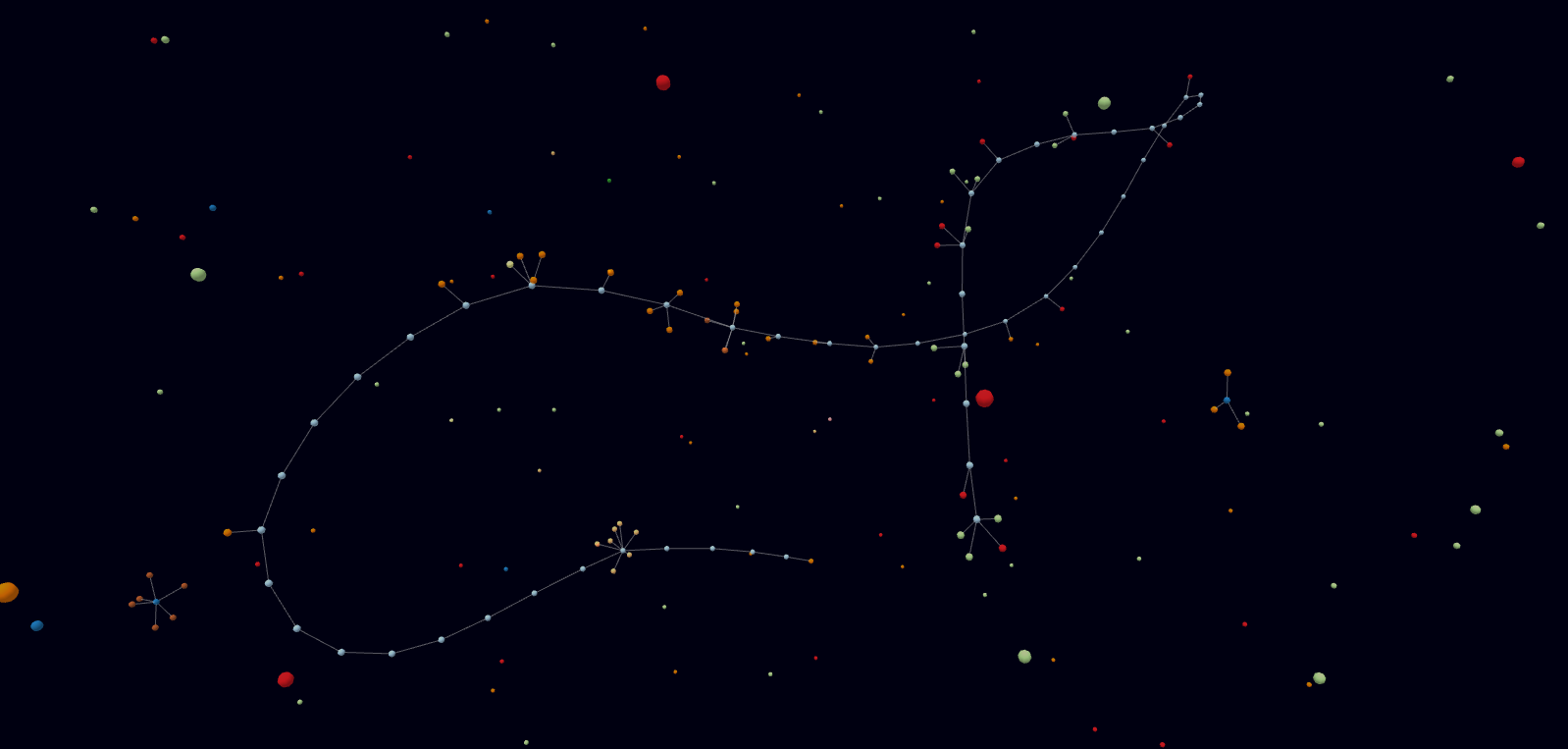
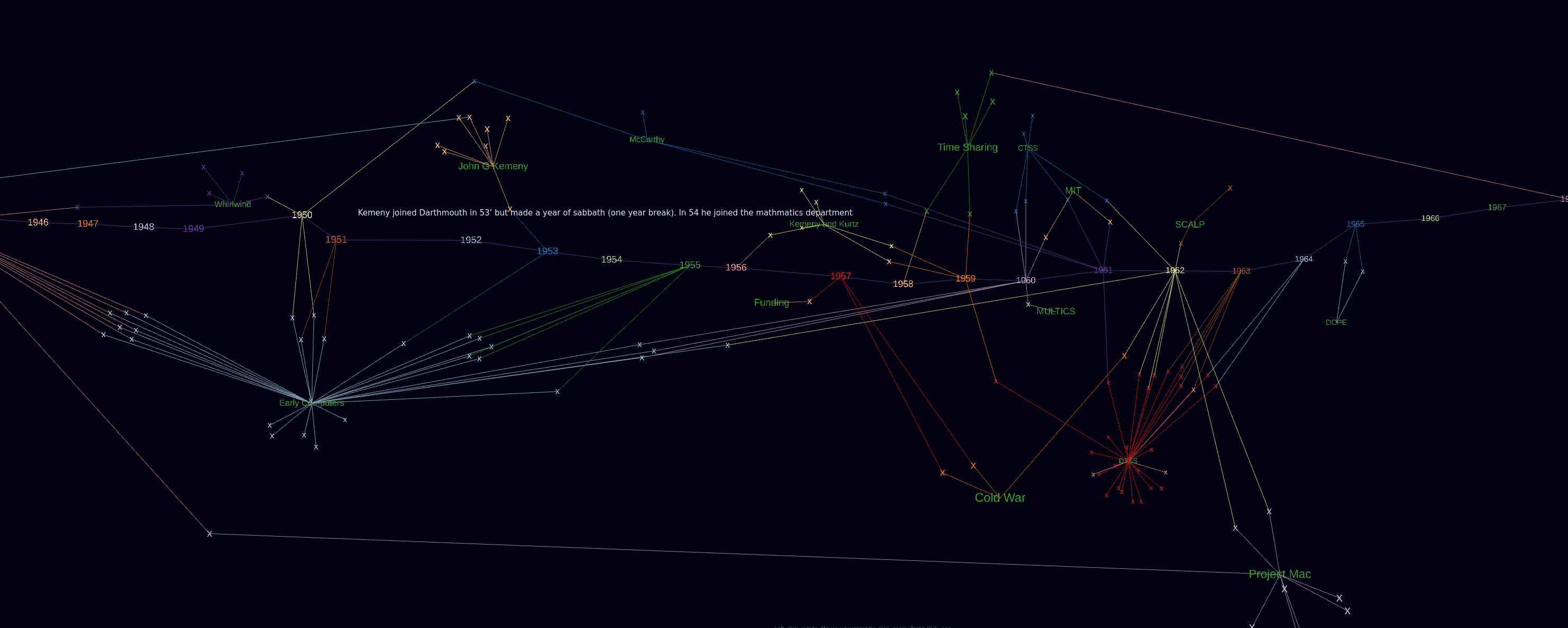
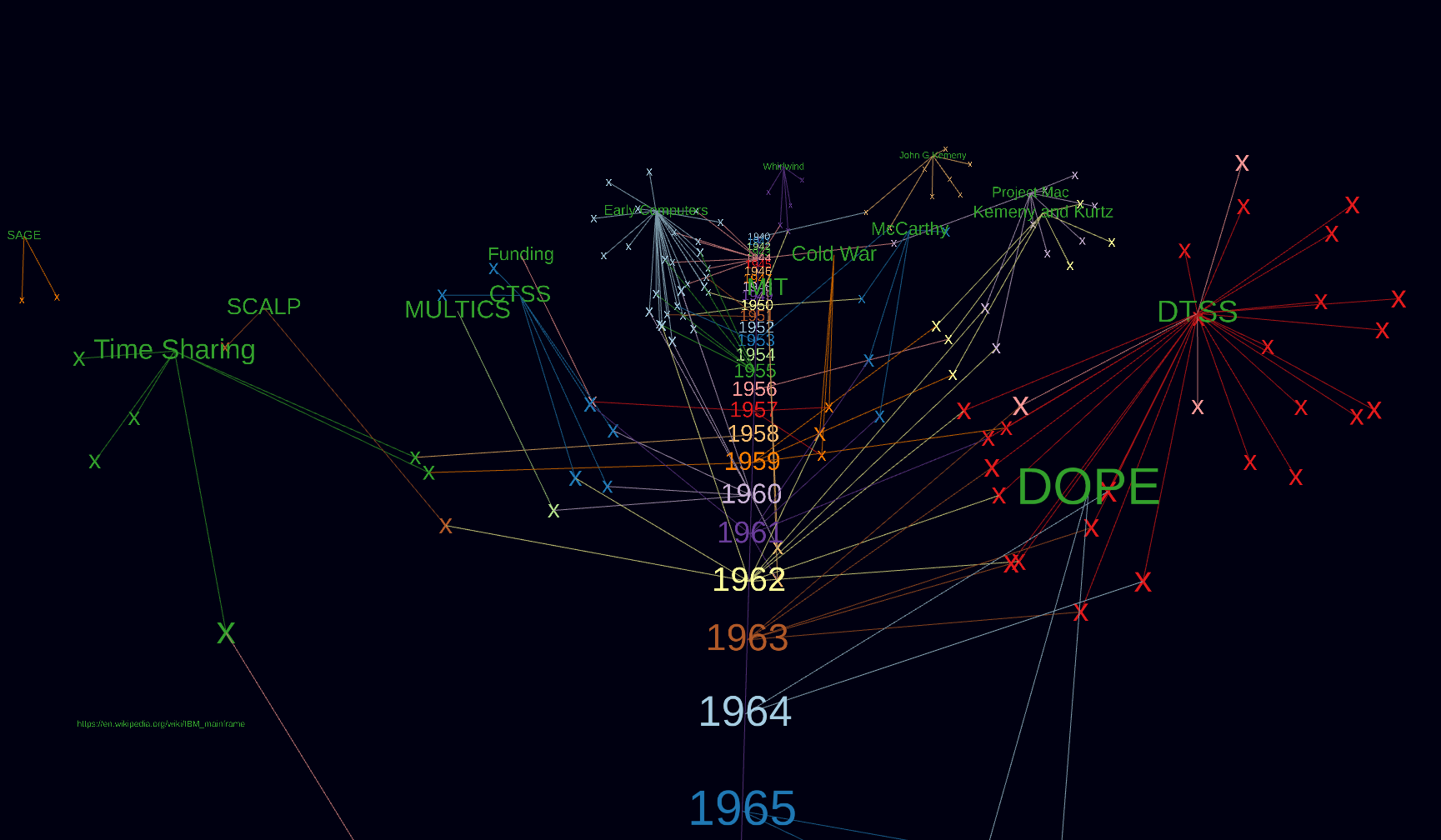
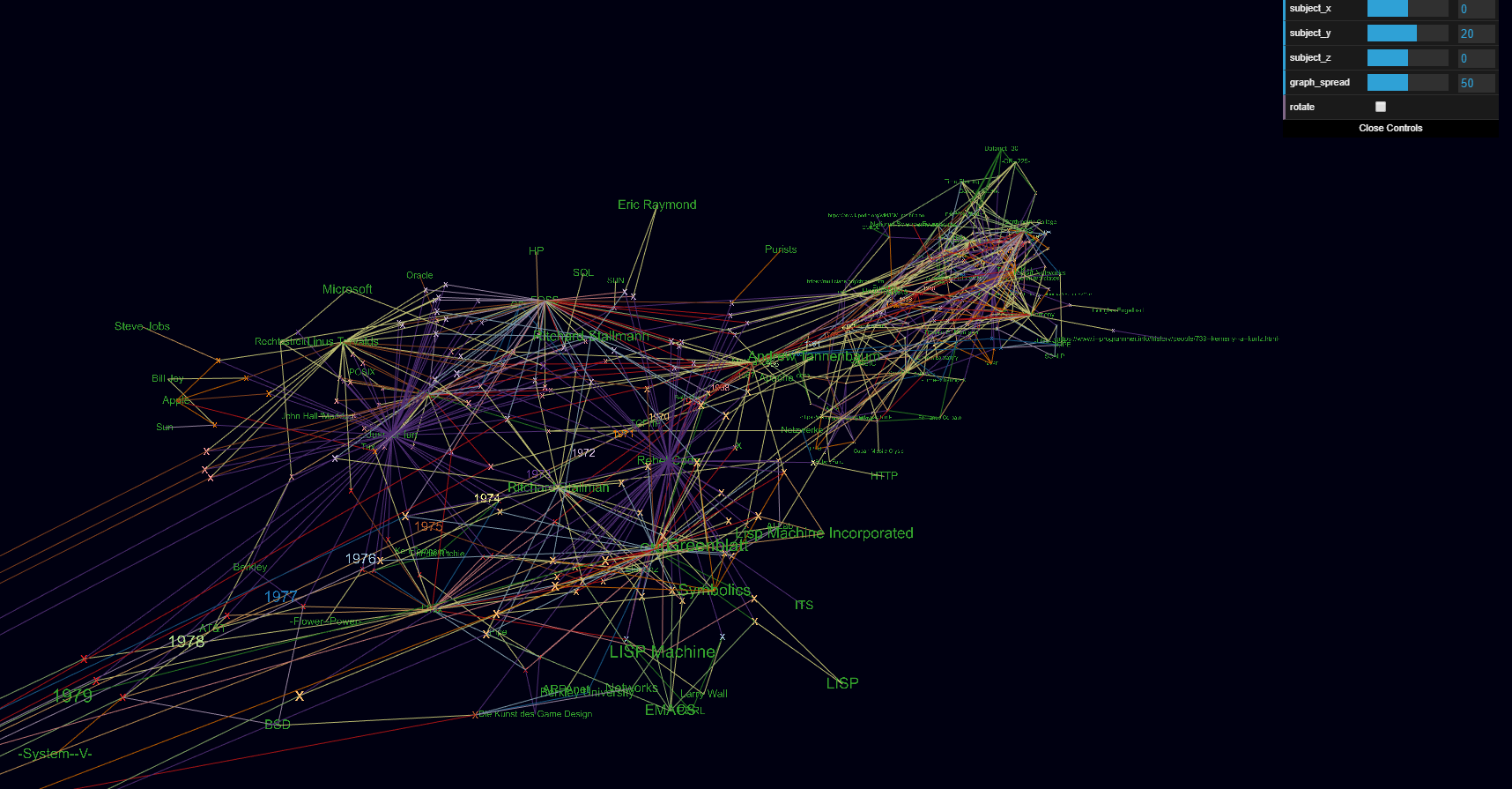
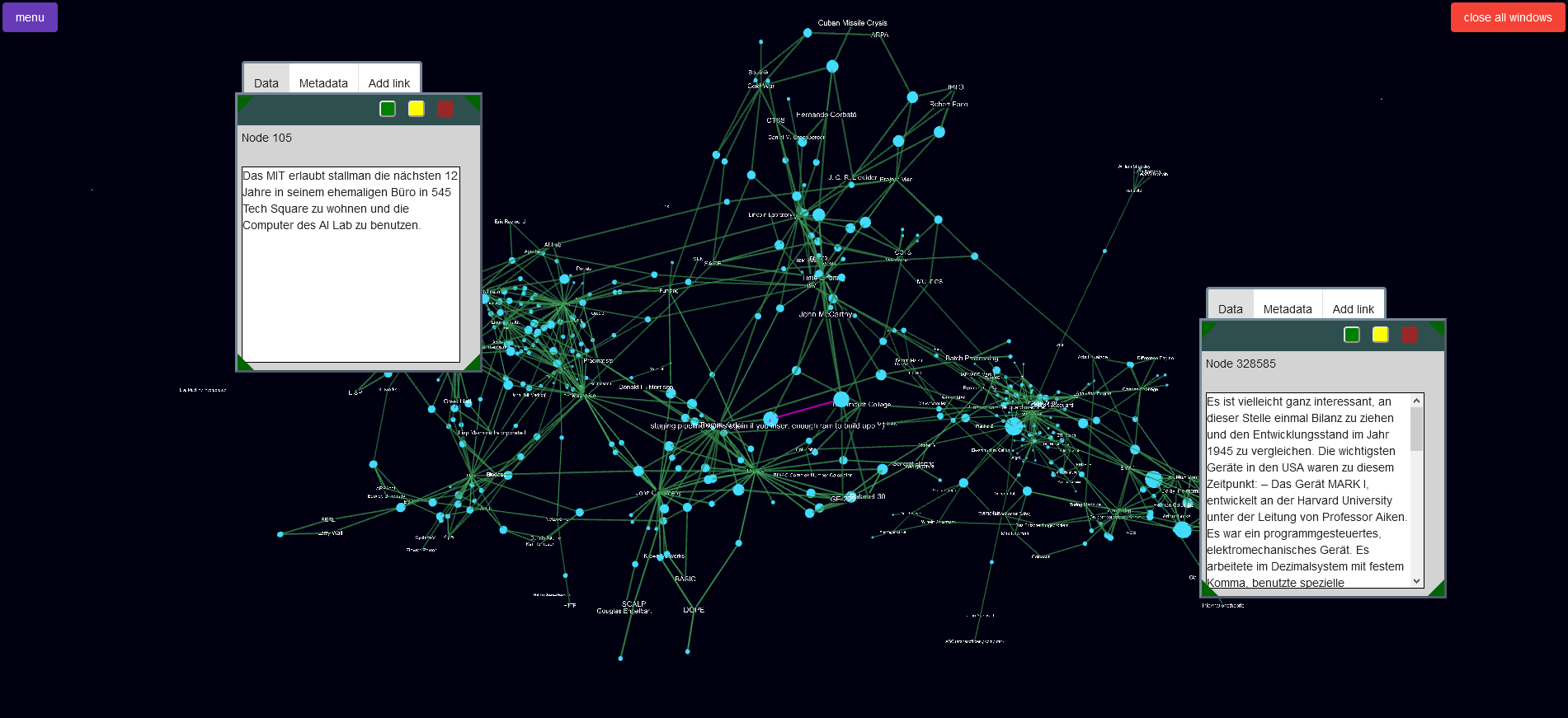
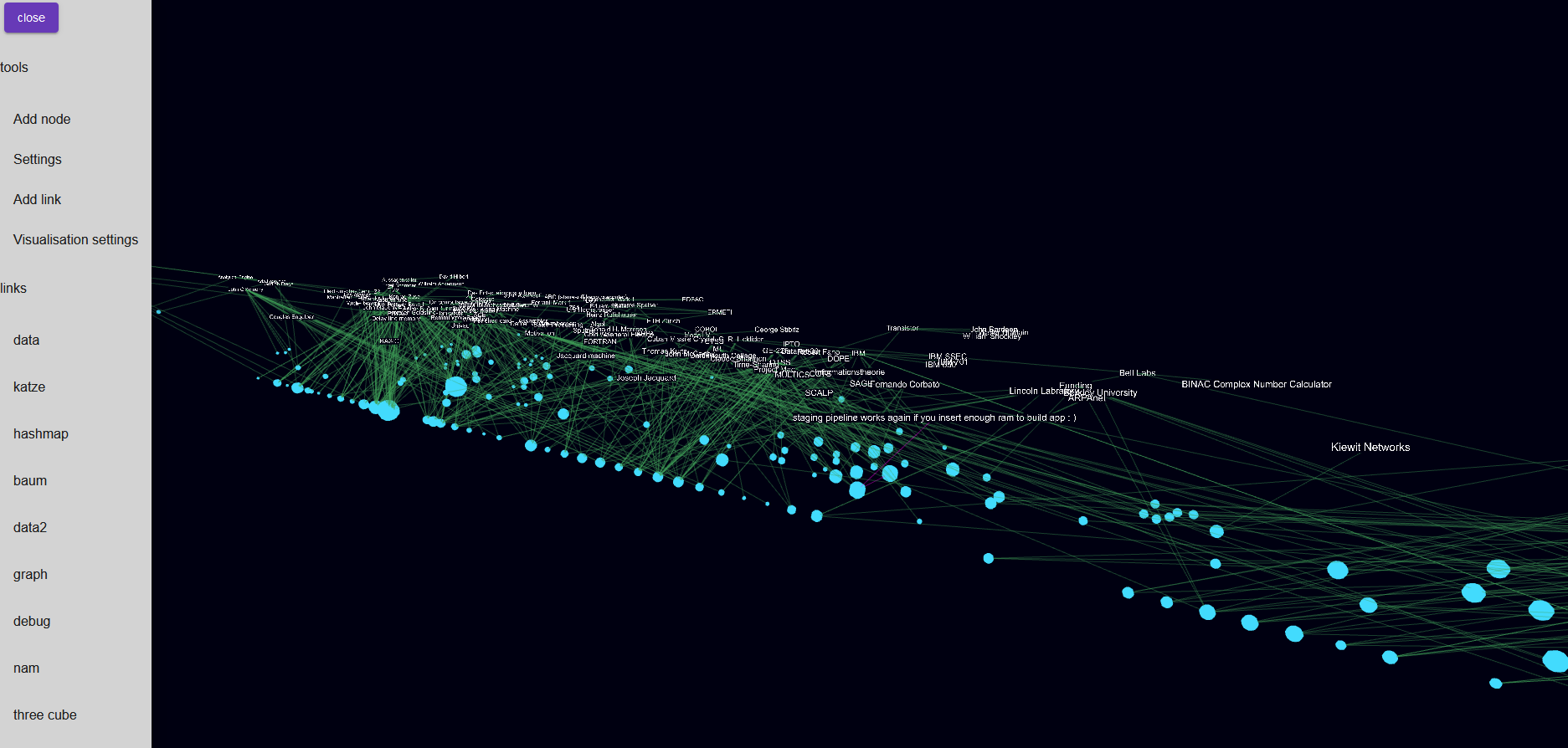
Meine Bastelei mit Forcegraph3d hat mich bisher hier ankommen lassen.
Da ich “nur” den Datensatz um 1960 halbwegs bisher halbwegs mit maschinenlesbaren Daten ergänzt habe, sind noch wenig Verbindungen von klar thematisch zusammenhängenden Themen zu erkennen.
Das wird mit Prüfung der Primärquellen und Verschlagwortung der Datenpunkte noch besser.
Jedes X ist ein Datenpunkt und mit einem Mouseover ist das Zitat lesbar.
Ich arbeite aktuell an:
- Zuordnen von Datenpunkten zu N Themen (aktuell ist jeder Punkt nur einem Thema zugeordnet)
- Fixieren von Informationen auf fixen Achscoordinaten
- Ein und Ausblenden von Informationstypen nach Filtern
- Verbindungen zwischen Quelle (Buch 1, Buch 2, Buch 3) und Datenpunkt
Mein Podcastpartner arbeitet daran, die Informationsquelle von CSV / JSON in eine Datenbank zu laden, damit das einlesen, editieren und korrellieren neuer Datenpunkte performanter geschehen kann.
Am ende wollen wir ein Werkzeug haben, in das wir eine irgendwo gefundene Information eingeben können, auf eine Art, dass sie unserem Gesamtbild automatisiert hinzugefügt werden kann.
Dadurch soll erkennbar werden, welche Personen mit welchen Meinungen zu welchen Zeitepoche an der Entwicklung welcher Projekte mitgewirkt haben, wie diese finanziert wurden, sich untereinander beeinflusst haben und welche Strömungen wie entstanden sind.
Diesen durchsuchbaren visualisierten Datensatz nehmen wir dann wieder her um uns auf die jeweilige Folge vorzubereiten.
Den zu erwartenden Blind Spots oder Fehlinterpretationen hoffen wir durch Interviews mit Fachleuten entgegenwirken zu können.
Ich hoffe ich konnte meine Ambition ein wenig verständlicher darlegen, als ich das anfangs gemacht habe. Sprache ist manchmal ein grausam unpräzises Werkzeug. Generell gilt: wir haben gefühlt für noch keine unserer Anforderungen das richtige Werkzeug gefunden. Wenn also eine Frage wie “warum nehmt ihr X und nicht Y” aufkommt, ist die Antwort wahrscheinlich “Weil wir nicht wussten, dass Y existiert oder es noch nicht als Lösungsansatz in Betracht gezogen haben.”
Um Y zu finden, bin ich hier 
Das Projekt ist ergebnisoffen und es spricht nichts dagegen, die Daten anders auszuwerten.
Gruß,
Ori